


Table of contents
- Introduction
- How does Liquibase work?
- Installation and connection
- Environment setup for this tutorial
- Configuration for an existing project
- Create new changelogs to control your object repository
- Existing projects only: Synchronize your database with Liquibase
- Existing and new projects: Tracking your database changes
- Deployment to PROD
- Liquibase tutorial: Summary
Introduction
Many organizations have implemented DevOps in their applications. At the same time, their database change process hasn’t evolved and is still left in the dark ages. But what if you could automate that, too?
It can be done using Liquibase, and here’s a Liquibase tutorial that shows you how to do it.
Supported databases
This tutorial focuses on configuring Liquibase for the Oracle Database, but the process and file organization are similar in the case of all other databases supported by Liquibase.
Liquibase supports around 60 databases, including Oracle, Microsoft SQL Server, PostgreSQL, Snowflake, Yugabyte, MySQL, and many others - the full list is here.
Is this tutorial for you?
Are you manually executing scripts to your database? Or maybe you’re wasting time validating database scripts received from your team?
After that, are you merging scripts into one file and executing them in every environment? How about deployment errors? Have you ever spent hours looking at who and why changed what in the database?
You can streamline all of the above using Liquibase.
But what if you can’t have an entire CI/CD process right now, or company policy doesn’t allow you to run scripts on specific environments? That’s not a problem for Liquibase, either.
By using Liquibase, you can:
Automate your database deployment scripts
Consistently deploy the same way in every environment
Have all detailed info on deployments in one place
Thanks to this, you will have:
Fewer deployment errors
Happy and efficient developers coding together on the same databases
Every change was audited, e.g., who, when (and why) changed the column SHOES.SHOE_SIZE from a NUMBER data type to a VARCHAR2
More coffee time ☕️
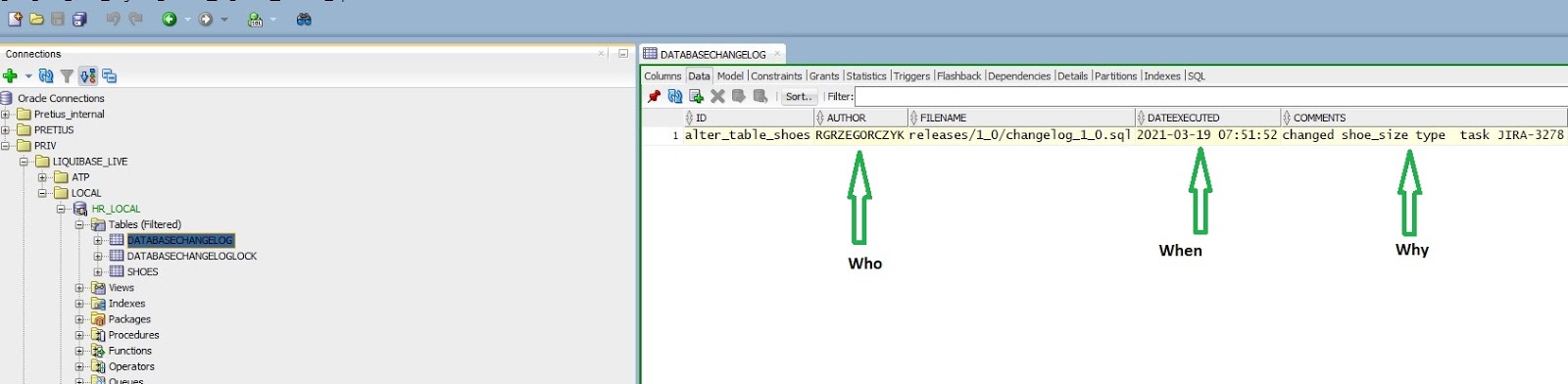
What is Liquibase exactly?
Liquibase is an open-source Java tool that makes defining database changes easy in a format that’s familiar and comfortable to each user. Then, it automatically generates database-specific SQL for you.
Database changes (every change is called a changeset) are managed in files called changelogs. My examples will be based on changes written in SQL – it’s the easiest way to start automating your Oracle Database change process.
Liquibase vs. Oracle SQLcl Liquibase - is it the same?
Please note that there might be some confusion regarding Liquibase. The open-source Liquibase supports multiple database providers, whereas SQLcl Liquibase is specifically designed for Oracle databases and is built on top of the open-source Liquibase. To learn more about the differences between SQLcl Liquibase and Open-Source Liquibase, you can read Zachary Talke's blog post here.
How does Liquibase work?
Now, let’s go through some basic terms and details to help you understand how Liquibase operates and what it does.
Changelogs
Liquibase uses changelog files (in SQL, XML, YAML or JSON formats) to list database changes in sequential order. Here’s an example of a changelog:
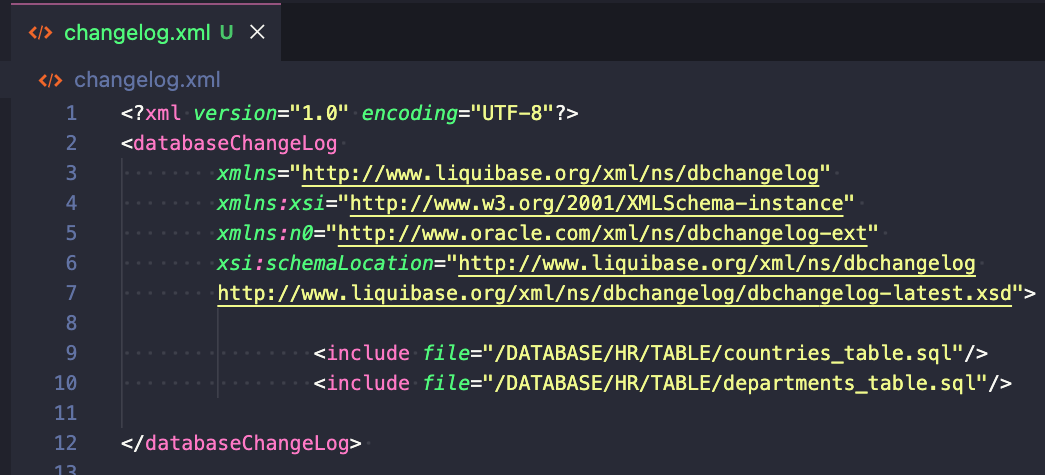
The above example includes a path to two other changelogs (countries*anddepartmentstables).*
Changesets
Database change is called a changeset. There can be many changeset types to apply to a database, such as creating a table, adding a primary key or creating a package.
File departments_table.sql is a changelog that contains two changesets:
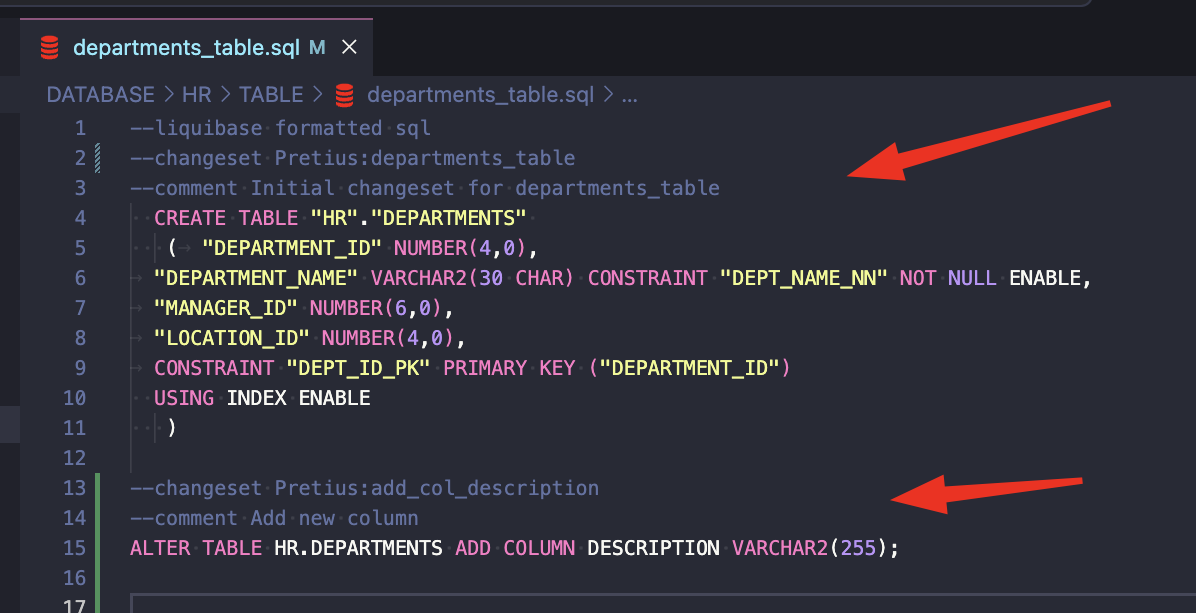
Legend:
- line 1 – --liquibase formatted sql is a syntax you need to add only at the beginning of every new SQL changelog. Liquibase requires it to identify changelogs
lines 2 and 13 – Those lines are identifiers that uniquely describe every changeset
Pretius – changeset author
departments_table and add_col_description – unique changeset identifiers (id)
lines 3 and 14 – these are comments. It’s an option, not a requirement
The author and id attributes and the changelog file path uniquely identify a changeset.
Tracking tables
Liquibase tracks which changesets have been run by using the DATABASECHANGELOG table. If the table does not exist in the database, Liquibase creates one automatically.
Liquibase will also create the DATABASECHANGELOGLOCK table. This table will be used to create locks to prevent simultaneous runs of Liquibase on your database.
That’s all the basics. You will learn more by reading this tutorial and the examples shown.
Installation and connection
The initial installation process is pretty straightforward. I won’t take you through it in this article, but I have several posts that’ll take you through it step-by-step:
Standalone installation of Liquibase on Windows/MacOS + connecting Liquibase to the Oracle Database (on-premise/cloud)
Installation of SQLcl with Liquibase isn’t necessary if you’re starting to use Liquibase in a completely new project. However, if you start with an existing project, later in the blog, I will describe how to "download" the current state of an existing database using SQLcl
Setting up UTF-8 coding – required if you are using Windows
Anyway, I recommend going through steps 1-2 (MacOS users) and 1-3 for Windows users.
Environment setup for this tutorial
I have 2 Oracle Cloud Autonomous Databases (free versions) – DEV and PROD
HR users with Human Resources objects are installed at both my DEV and PROD environments (I downloaded HR objects from a sample Oracle repo)
Some other sample objects available here will also be used in this tutorial
SQLcl is installed in version 23.4 (it will be used only once – to prepare an existing project for Liquibase usage)
Standalone Open Source Liquibase 4.25.1 is installed
My GIT root repository folder, shown in further screenshots, will be called LIQUIBASE_TUTORIAL
A public GIT repository with files shown in this tutorial is here
I use Visual Studio Code to make working on files easier
I use the FORK client for working with GIT repositories
Configuration for an existing project
Now, I’ll show you how to configure everything for your existing project(with Oracle database). There are a couple of steps you’ll need to take.
Make sure your environments are equal (DEV=UAT=PROD)
It is recommended that your environments are equal before using Liquibase. There are two ways I usually recommend doing this.
If you think that differences between your databases are huge and out of control, you should use the Oracle Data Pump:
Stop all development work or finish it and deploy it to PROD with your old process
Drop old schemas such as DEV and/or UAT.
Export actual PROD schema using Oracle Data Pump
Create new DEV/UAT using exported PROD schema
Anonymise data if necessary (or, in point 3, export only the structure / exclude some objects)
Or, if you suppose the databases are quite equal and it won’t take much of your time, you can just do everything manually.
Use SQLcl Liquibase to capture the current schema
I created a folder DATABASE/HR/, which I will use to capture my current schema from my HR_DEV environment. I will use SQLcl Liquibase for that.
Go to [YOUR_REPOSITORY_ROOT]/DATABASE/HR/ folder. In my example, it is LIQUIBASE_TUTORIAL/DATABASE/HR/. Connect to HR_DEV database.
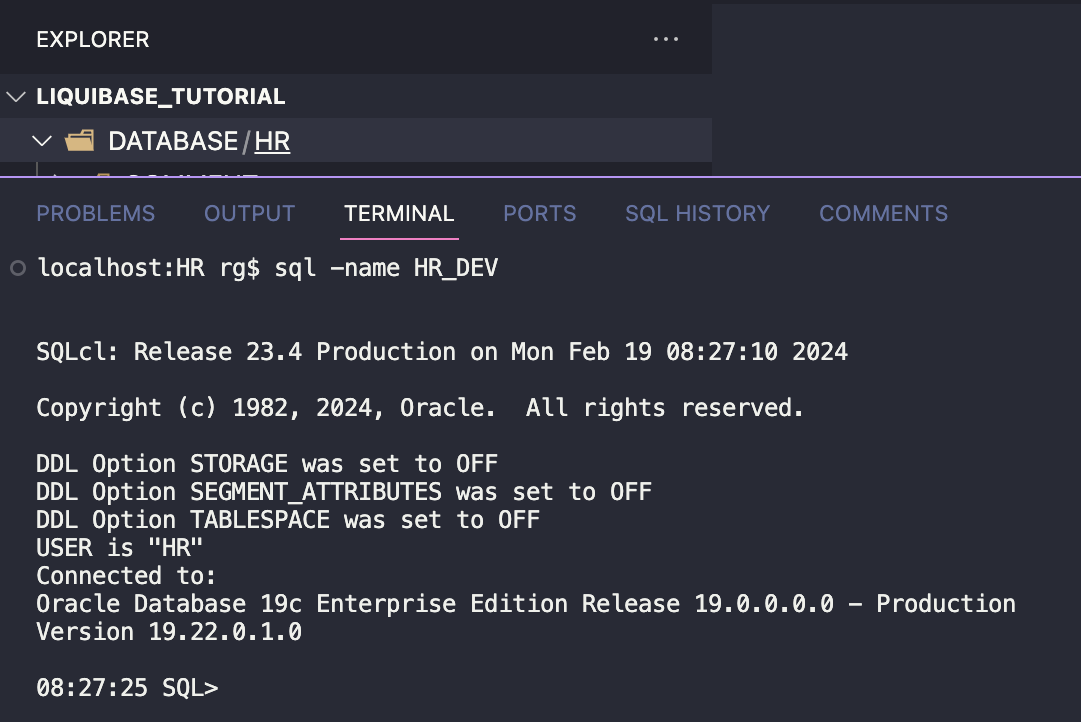
To capture all my HR schema objects, you can use the generate-schema command:
liquibase generate-schema -split -sql
Depending on the size of your database, it may take from a few minutes to up to 1-4 hours.
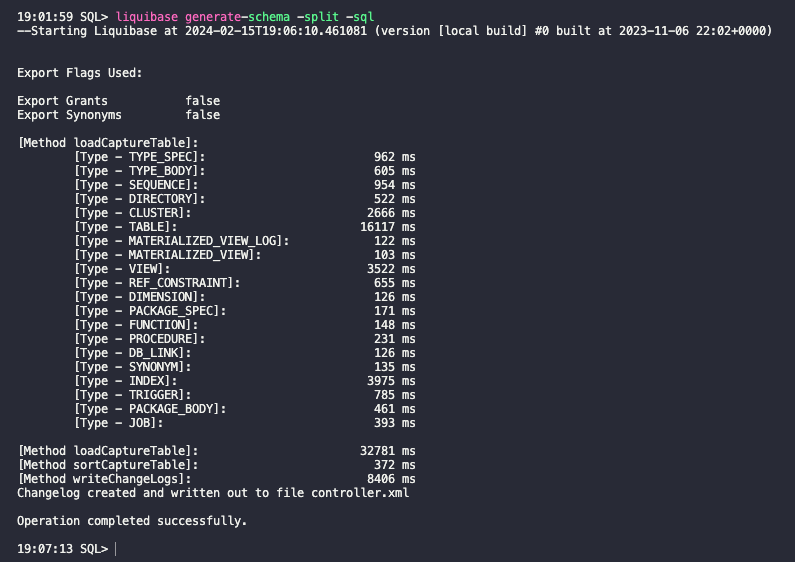
SQLcl Liquibase automatically generated all my schema objects in separate folders. Files were generated in XML and SQL formats.
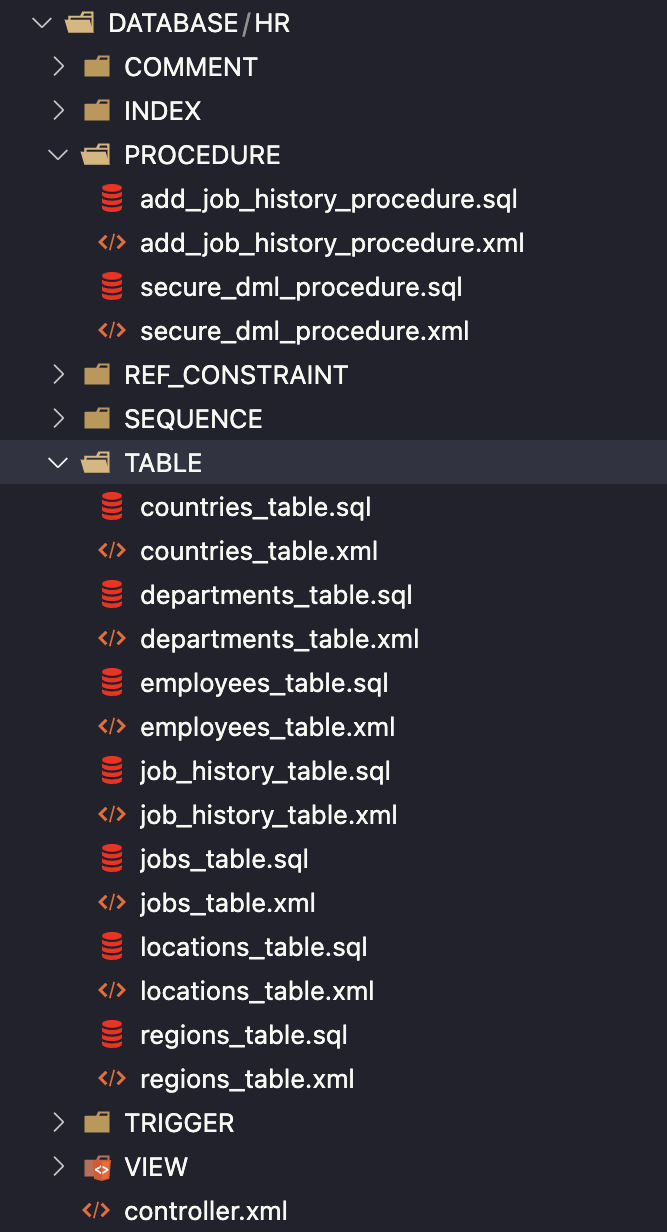
The XML format is great and provides many more Liquibase functionalities, but I will not use it in this tutorial (read more about XML formats in the documentation). That’s why I need to remove all generated XML files. There are two ways to do this.
Once again, you can do everything manually if you don’t have many files. Alternatively, you can use the attached power shell script that will do it for you if your database is big:
Go to the repository for this tutorial and copy script HELP_SCRIPTS/POWERSHELL/remove_xml_files.ps1 to your root folder (LIQUIBASE_TUTORIAL in my case)
It will remove all XML files from your /DATABASE/ folder and subfolders
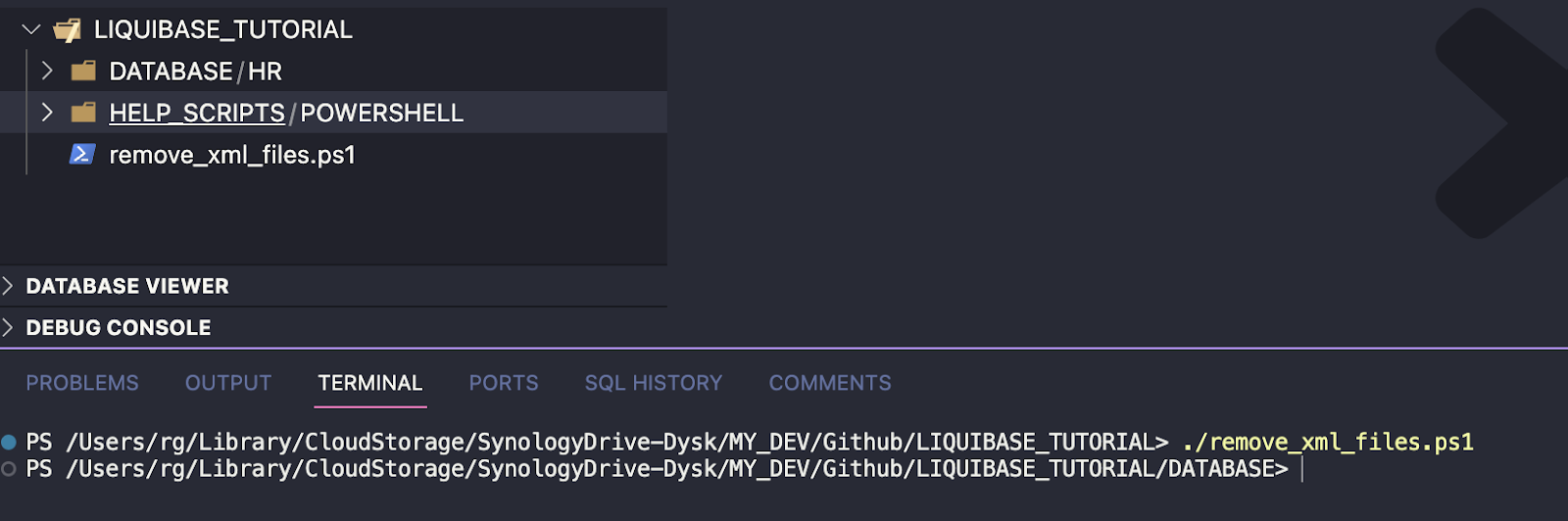
As a result, I only have SQL files in separate folders.
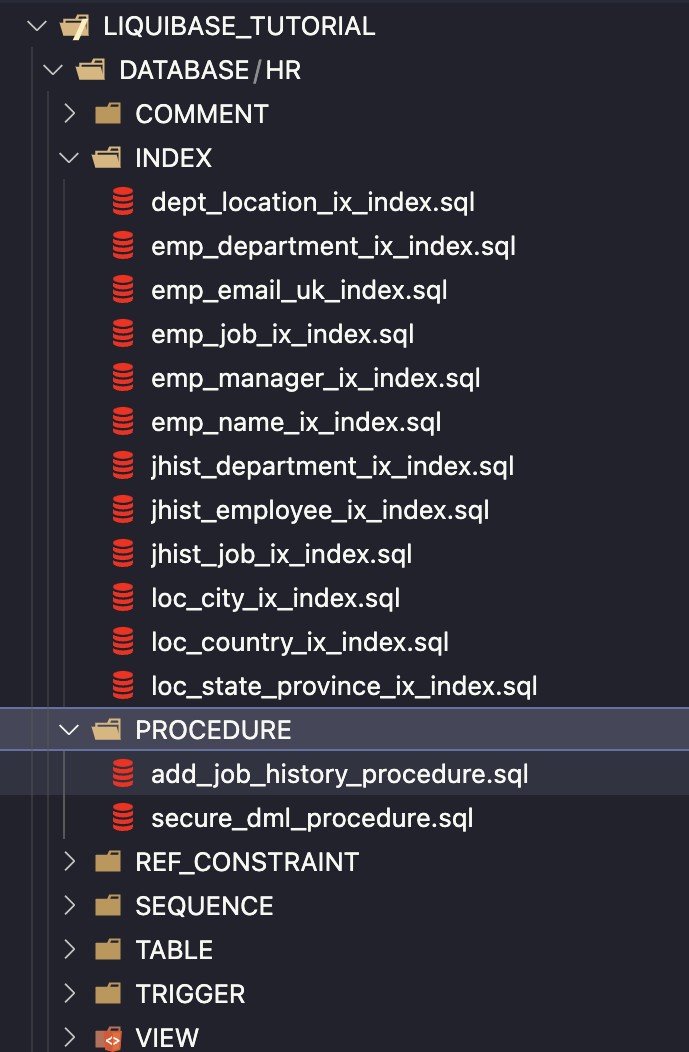
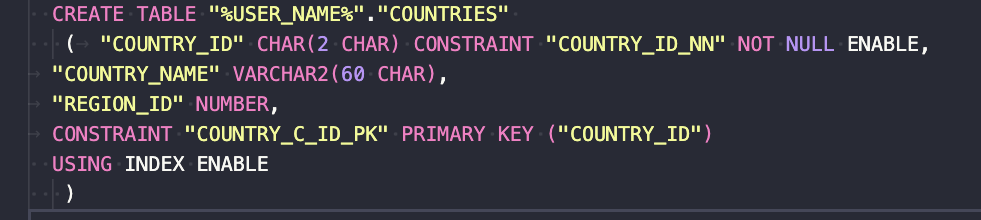
Adjust auto-generated SQL files for further usage with Liquibase – remove the "%USER_NAME%" string (it’s a confirmed bug in SQLcl 23.4) from all SQL files and replace it with your schema name.
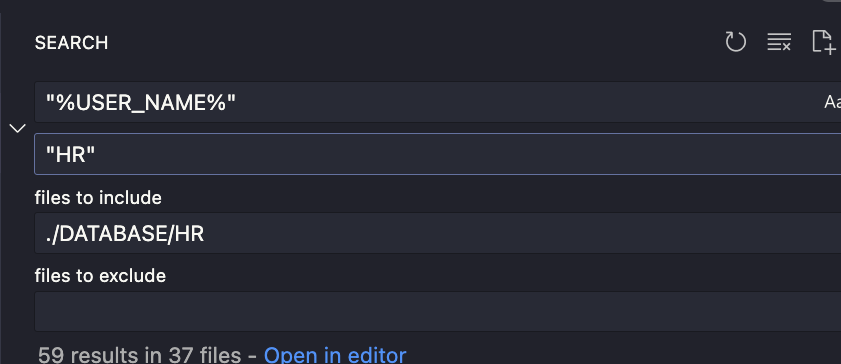
Add Liquibase syntax to all auto-generated SQL files (existing projects only!)
If you work with an existing project, you must add Liquibase syntax to all auto-generated SQL files. You can do this manually or use my PowerShell script.
Go to the repository and copy HELP_SCRIPTS/POWERSHELL/add_changesets.ps1 to your schema folder (in my case, it’s DATABASE/HR/)
Adjust the script if necessary, but create a backup of your folder first!
Execute the script using PowerShell

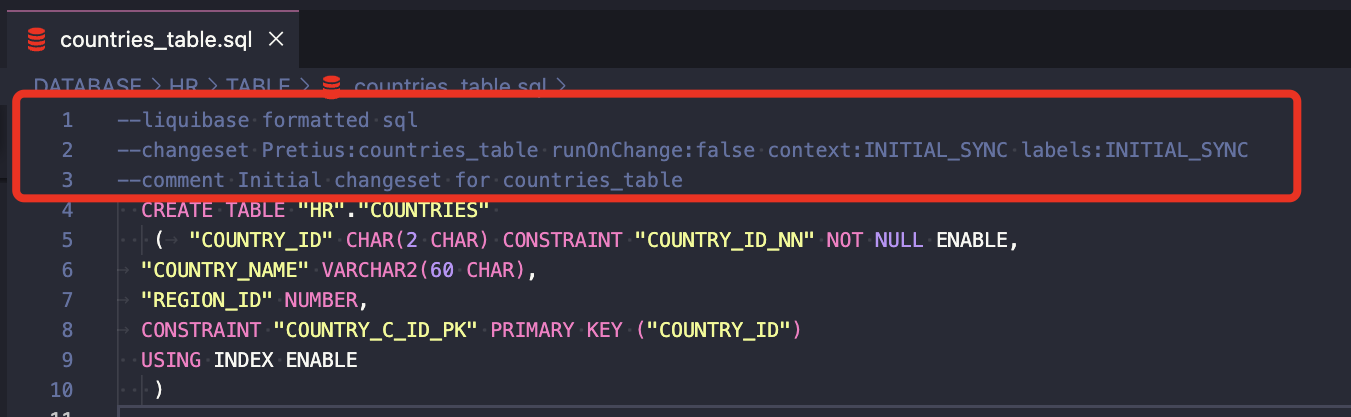
- A few seconds later, every SQL file in your repo will have auto-added syntax like this:
Create new changelogs to control your object repository
Now, let’s create changelogs to control your object repository. This step is necessary for both existing and new projects.
- I will create my main changelog file master.xml, which will be responsible for the order in which my files are executed. This file will be located in my root directory:
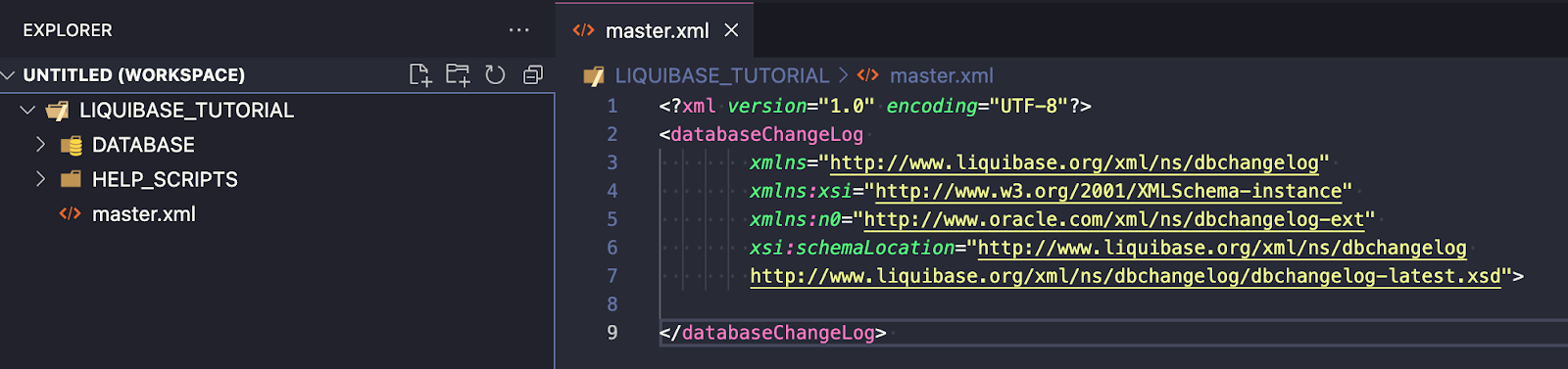
- Now, I need to point to my folders with specific types of objects. This is an important step because the way you write it in master.xml will be the order of execution. I will use a folder structure that was automatically generated while capturing the schema of my current project (see above).
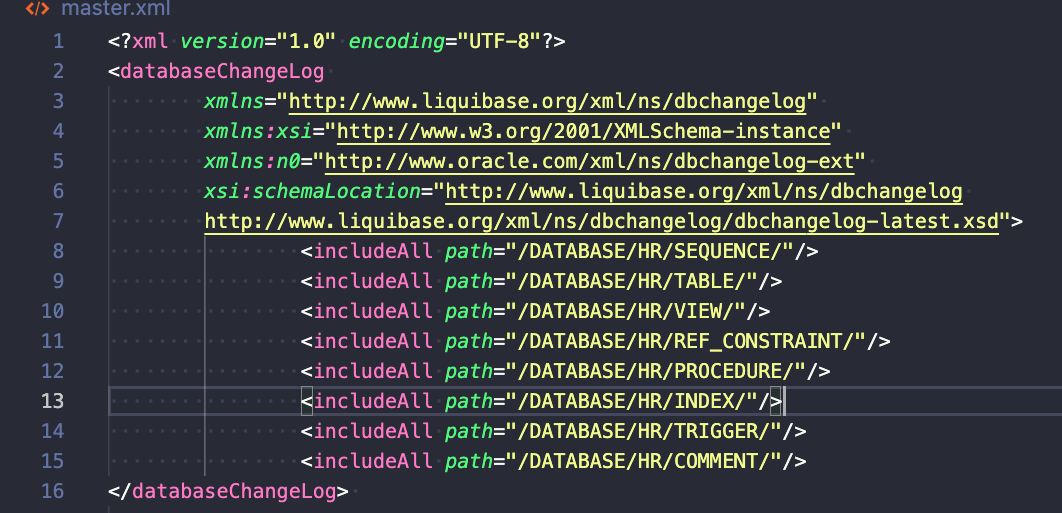
Legend:
- includeAll – execute all files from the location provided in alphabetical order. Please remember that PKB or PKS files are not supported – I prefer using SQL or XML only. In the above example, all files from the /SEQUENCE/ folder will be executed first, in alphabetical order.
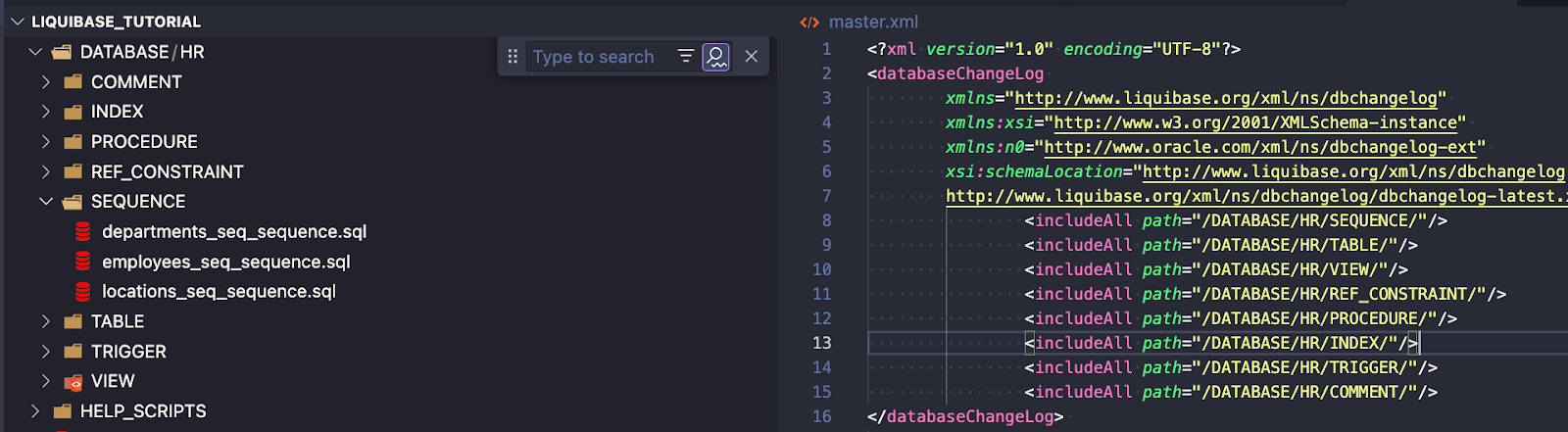
- includeFile – using this tag, you explicitly say which file (changelog) should be executed. It gives you more control over the order execution of your files.
To show you how to use includeFile, I prepared an example for all my procedures inside the /DATABASE/HR/PROCEDURE/ folder:
- From master.xml, I remove includeAll linking to this folder and replace it with includeFile tags.
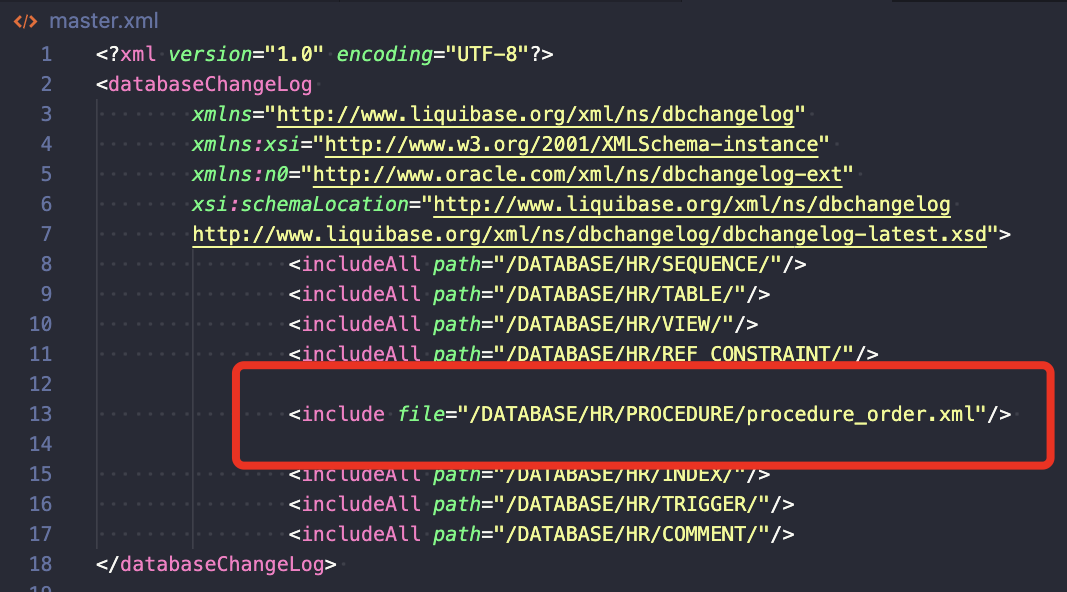
- The next step is to create procedure_order.xml changelog in the /DATABASE/HR/PROCEDURE/ location
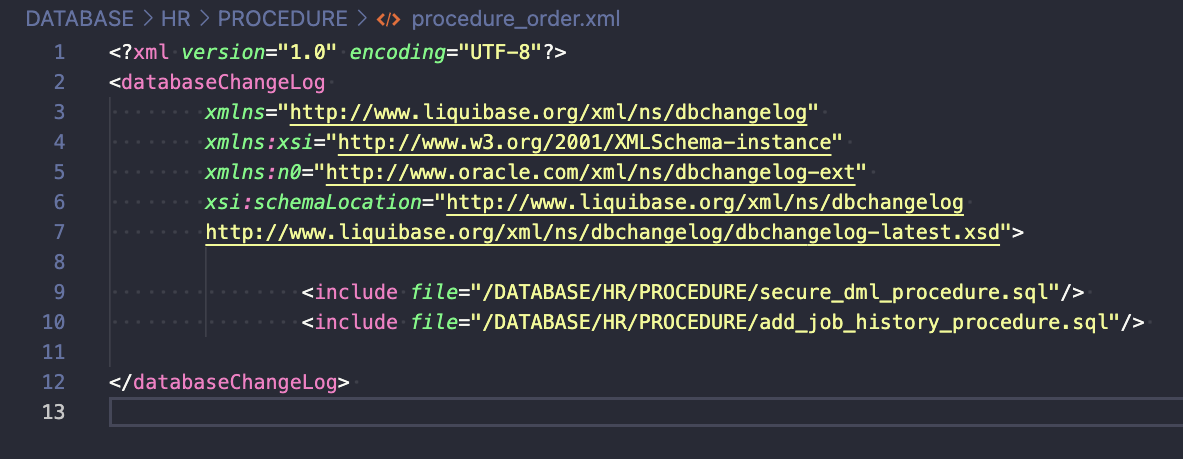
In this example, I explicitly say what file should be executed in which order.
You can create such changelogs for all your folders and use as many changelogs as you want.
Create connections to DEV and PROD for standalone Liqiubase
I have created two connections using the installation tutorial from the beginning of this guide. One for DEV and one for the PROD environment.
Existing projects only: Synchronize your database with Liquibase
The next step is to synchronize your existing database with Liquibase – of course, this will only be necessary for existing projects. This aims to “tell” Liquibase that all files in your repository already exist in your database, and those files should not be executed until someone changes something in the code.
My two environments, DEV and PROD, are now equal, so I need to synchronize them. This is only a one-time step when you start using Liquibase in your existing project.
The changelog-sync command marks all changes in your changelog as executed in your database (read more in the Liquibase documentation).
Execute at DEV environment:
liquibase --defaults-file=dev.liquibase.properties --changelog-sync-sql
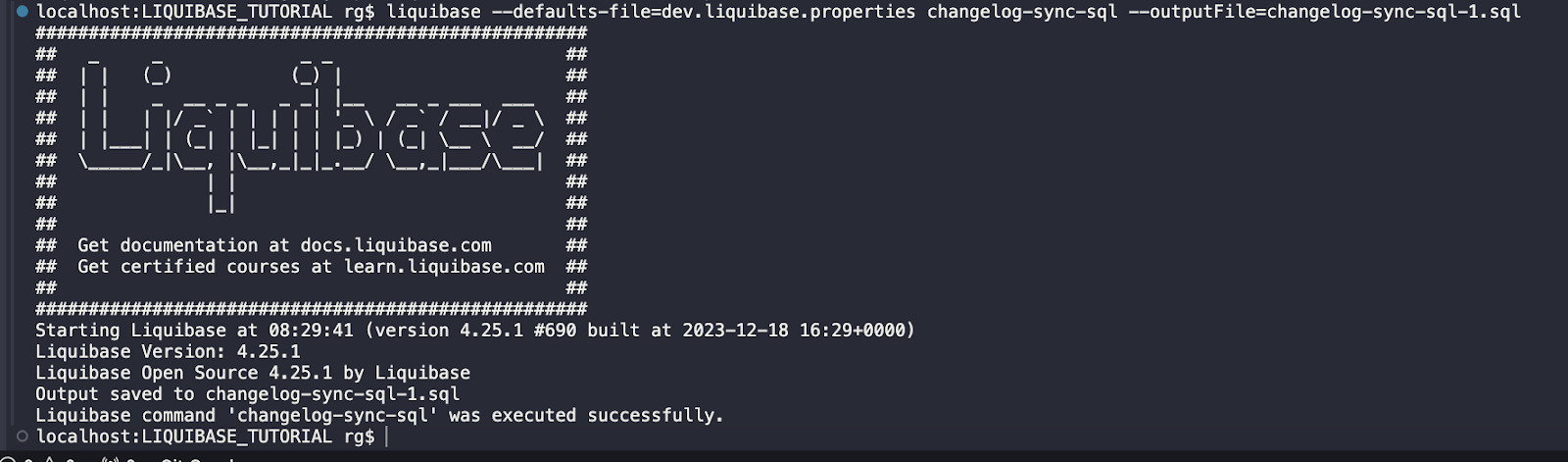
I used the changelog-sync-sql command first to generate an SQL file and verify what would be executed when running the changelog-sync command.
I did not use filtering by labels, e.g., --label-filter=INITIAL_SYNC, because, at this moment, I want to capture all my changes.
However, if my command was like this, the result and the output file would be the same:
liquibase --defaults-file=dev.liquibase.properties --changelog-sync-sql -label-filter=INITIAL_SYNC
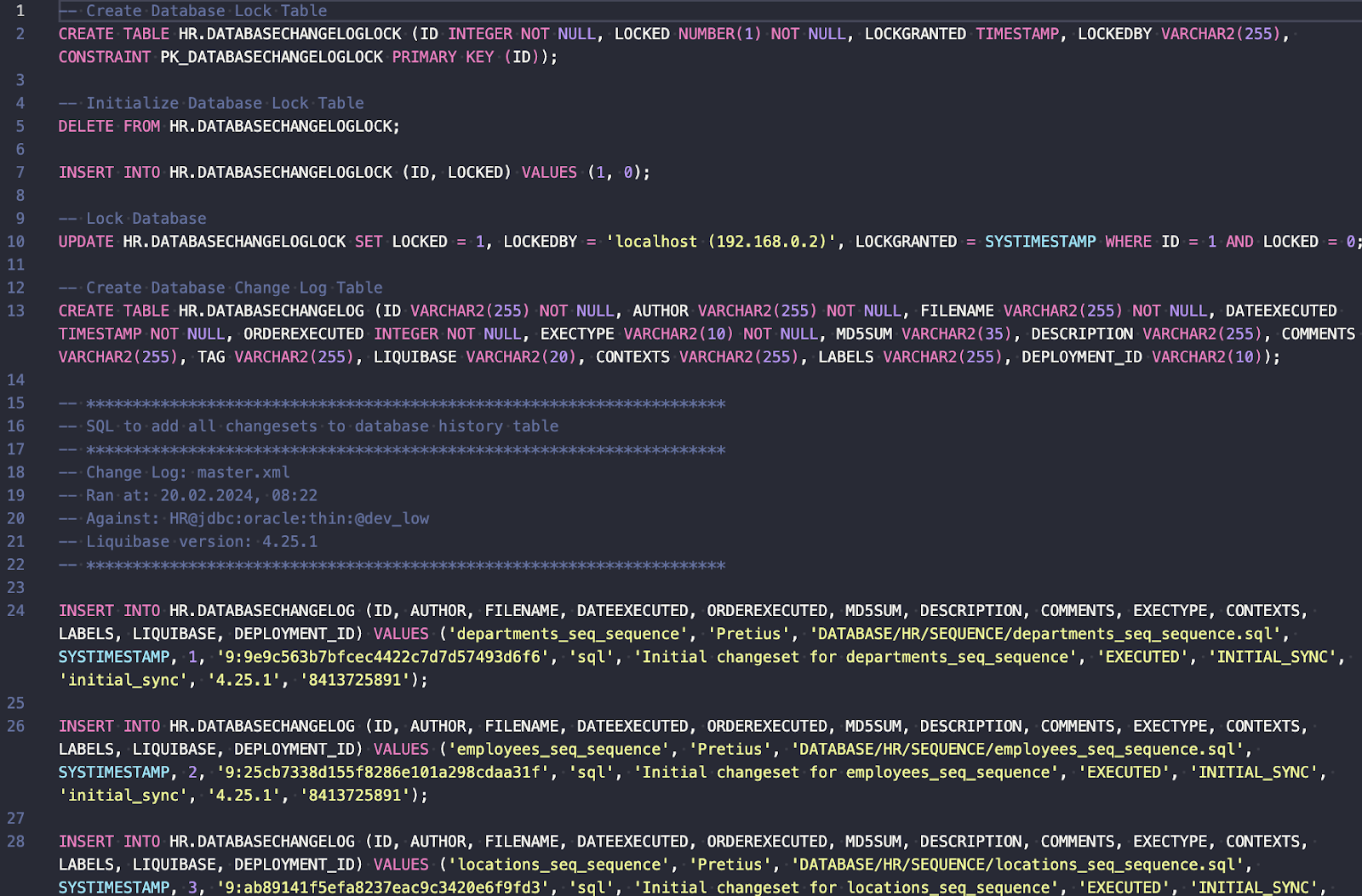
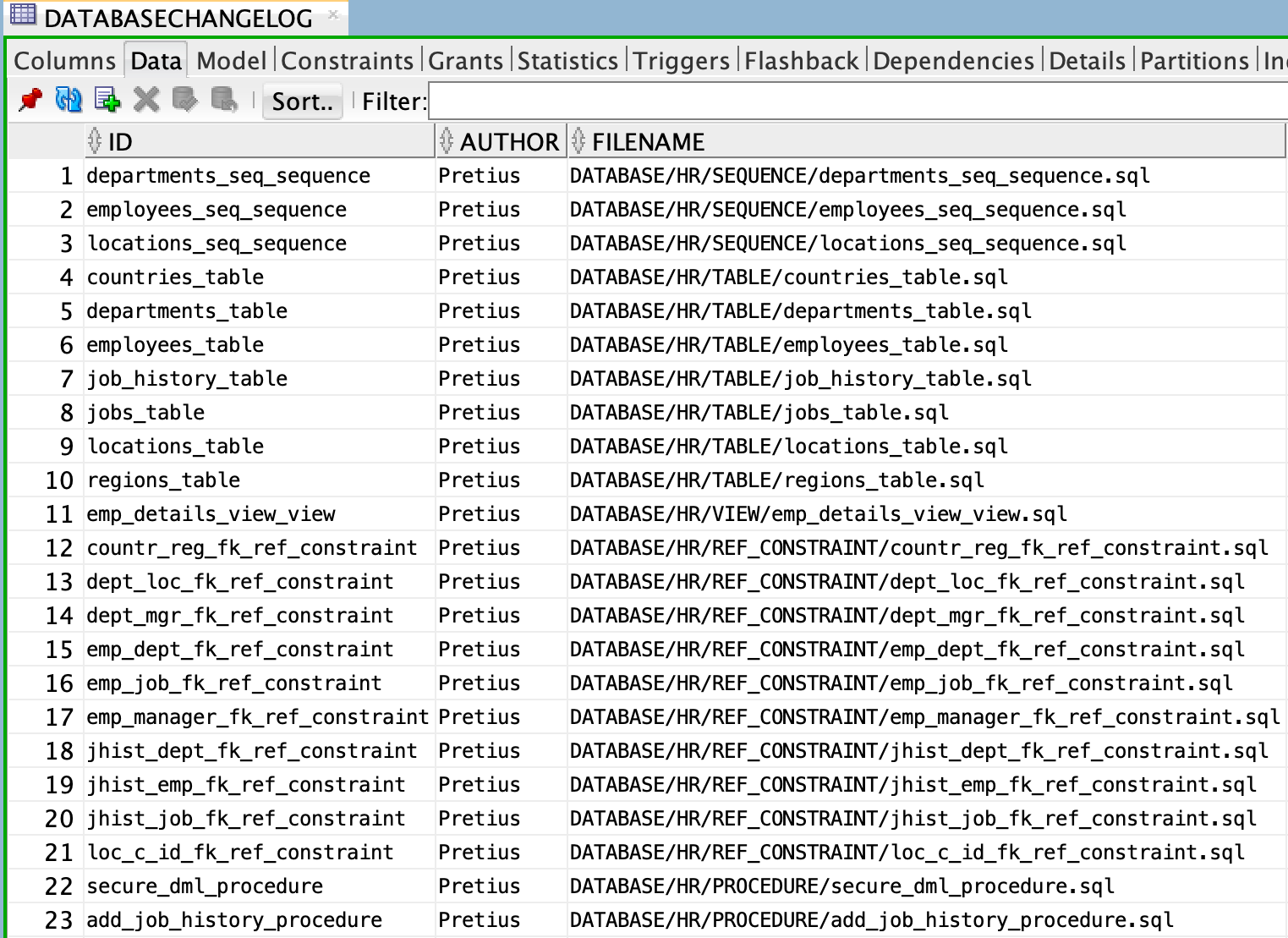
As you can see, Liquibase will create DATABASECHANGELOGLOCK and DATABASECHANGELOG tables because this is the first Liquibase run.
Moreover, many rows will be inserted into the DATABASECHANGELOG table, marking all the changesets as already executed.
No other database code will be executed – no changes to existing objects yet. You can see the full script generated here.
It’s a good habit to run commands with -sql first and preview what happens first instead of executing unintended code.
Now, I will execute the changelog-sync command.
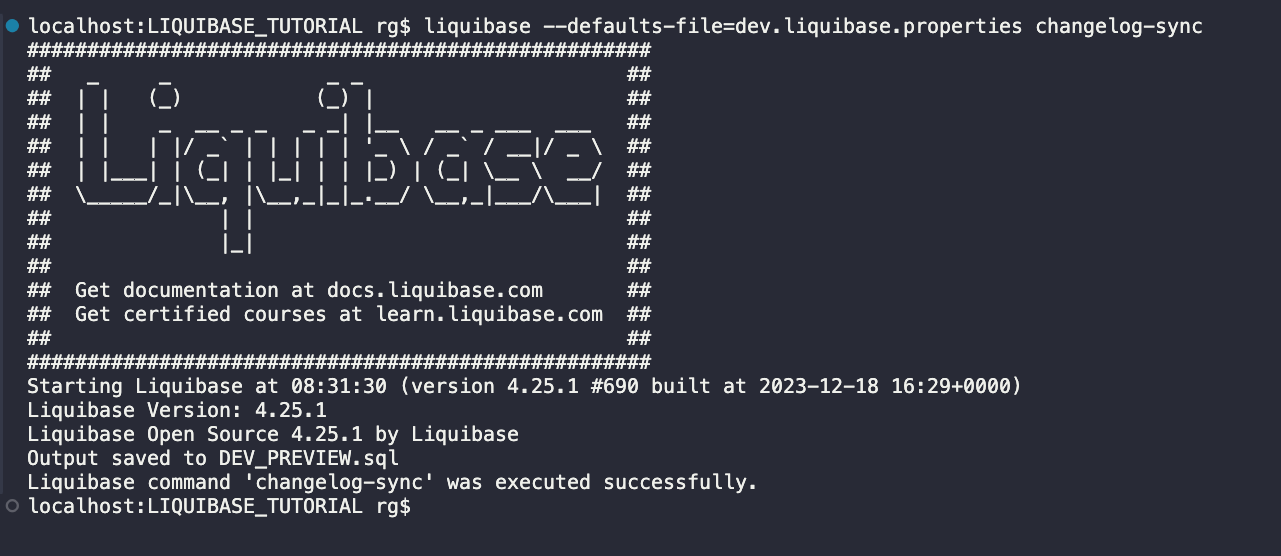
Two tables were created, and rows were inserted into the DATABASECHANGELOG.
Repeat the above steps in the PROD environment:
Before repeating the steps, remember to change your connection file.
liquibase --defaults-file=prod.liquibase.properties --changelog-sync-sql
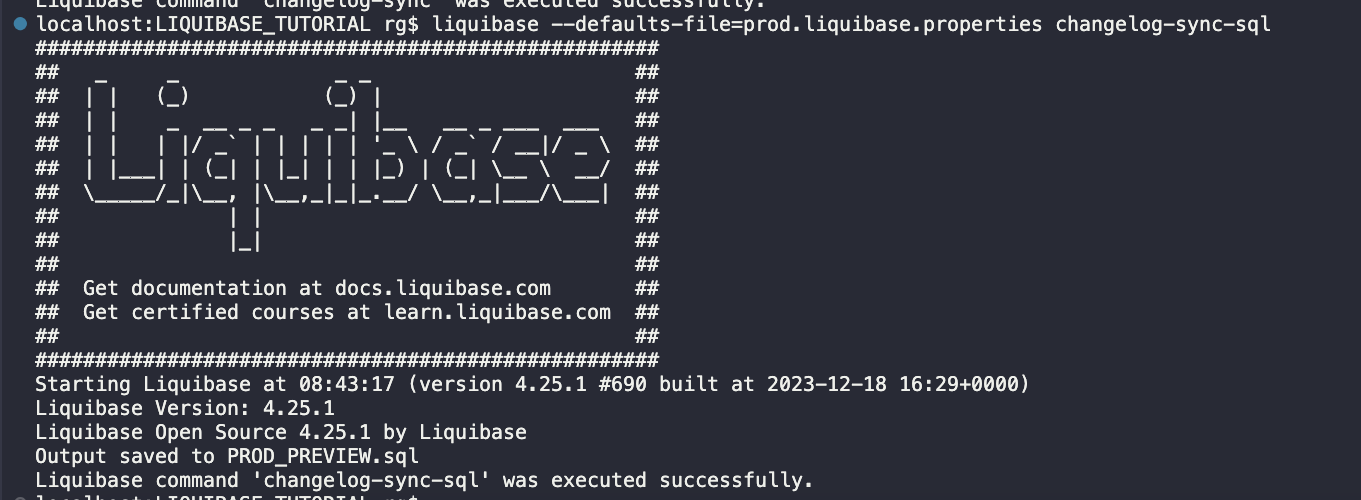
The preview file was ok, so I will execute changelog-sync.
liquibase --defaults-file=prod.liquibase.properties --changelog-sync
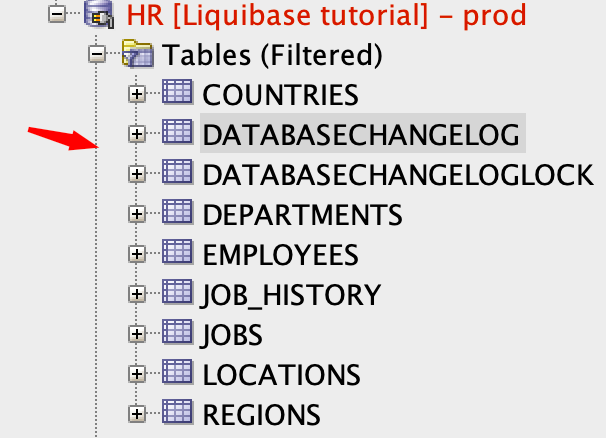
The result is the same as on DEV – two tables were created, and rows into DATABASECHANGELOG were inserted. Your existing project is ready for further work with Liquibase.
To sum up, what we did:
Using Oracle’s SQLcl Liquibase, we captured the current state of a database into SQL files
SQL files were adjusted to work with Liquibase (added required syntax – manually or using attached PowerShell script)
We executed changelog-sync command at DEV and PROD environments
We made sure that DEV and PROD are equal environments (same objects, data can differ)
When it comes to GIT:
All my files are in the GIT repository and represent an actual baseline of my databases
Files should be at GIT branches DEV and PROD. Those branches should be equal at this moment
Existing and new projects: Tracking your database changes
Okay, you have your GIT repository and database configured with Liquibase. From now on, all your database changes will be tracked.
Because of this, you SHOULD NOT change any of your database objects directly in your database (whether it's by SQLcl, SQL Developer or any other tool). Every change should go through a change in the SQL file in your repository and execution of the proper Liquibase command.
In the next part of this tutorial, I will make different changes to my database to show you how to create changesets and write appropriate syntax. All files and changes I will make are available in the public repository created for this tutorial.
First, all changes will be created and executed in the DEV database. After successful tests, changes will be released to PROD.
Quick reminder: a changeset is a change type to your database, e.g., creating a table, altering a table, creating a package, etc.
To deploy changes, I will use the UPDATE command. It’s a really good practice to specify only one type of change per changeset. It avoids auto-commit statements leaving the database in an unexpected state. When running the UPDATE command, each changeset either succeeds or fails. If it fails, you can easily fix it and deploy it again. You should also add comments to your changesets to explain their importance.
What is the Liquibase UPDATE command, and how does it work?
But first, let’s define what the UPDATE command really does. It deploys any changes in the changelog file that have not been deployed to your database yet.
It’s worth mentioning that Liquibase doesn’t check anything in your database objects. It won’t check if your table, column, or package exists or what version of the object resides in your database. However, if you try to create a table that exists, Oracle will throw an error during Liquibase execution. So, how does Liquibase know what should be deployed?
When you run the UPDATE command, Liquibase sequentially reads changesets in the changelog file, then compares the unique identifiers – id, author, and filename path – to the values in the DATABASECHANGELOG table. There are at least 3 possible scenarios that may happen after running the UPDATE command:
Your changeset’s syntax is incorrect ( incorrect SQL or PL/SQL), and your Oracle Database will throw an error.
If the unique identifiers don’t exist, Liquibase will apply the changeset to the database.
If the unique identifiers exist, the MD5Sum (file checksum stored in the DATABASECHANGELOG.MD5SUM column) of the changeset is calculated and compared to the one in the database. If they are different, Liquibase will produce an error message. Read more about checksum calculation here.
If you add this to the existing changeset, it will fail:
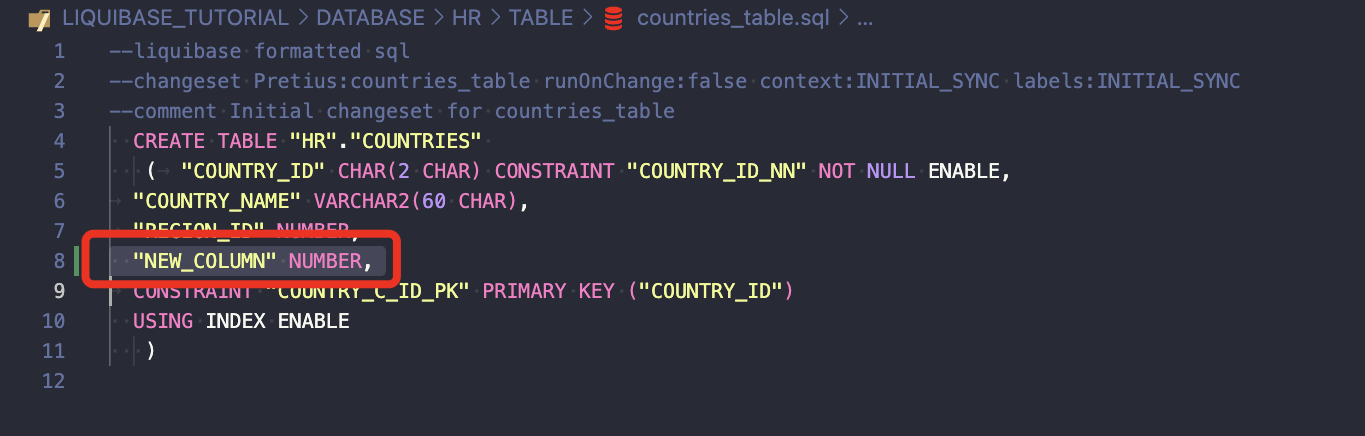
This is fine:
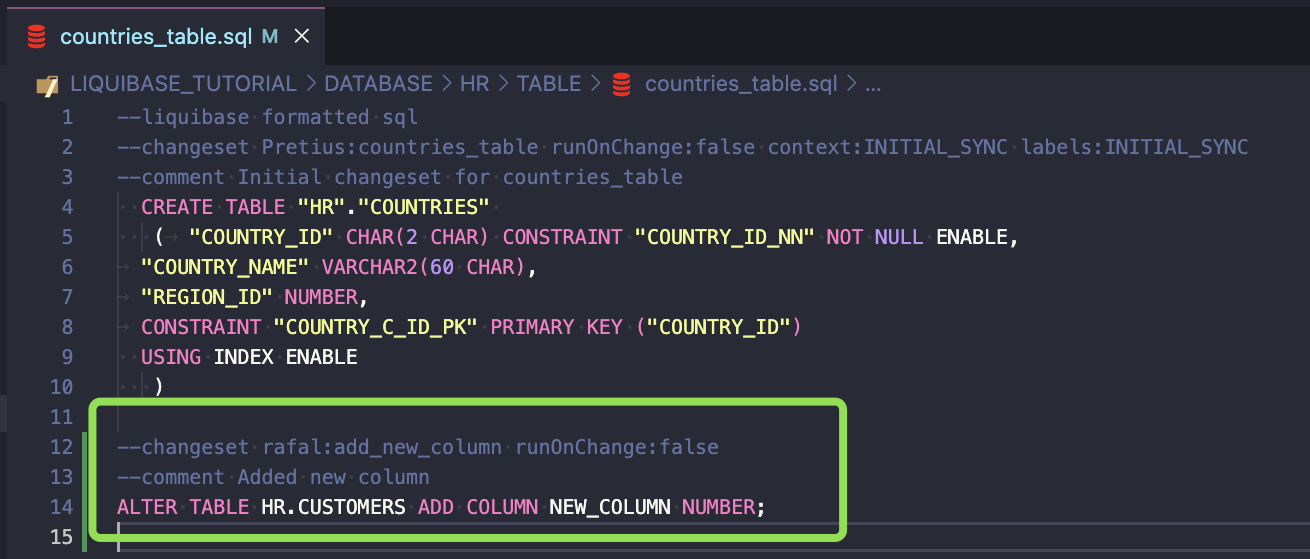
However, if runOnChange is set to TRUE, Liquibase will re-apply the changeset.
Remember that this param should be set to TRUE only for objects that can be replaced, like views, packages, procedures, functions, etc.
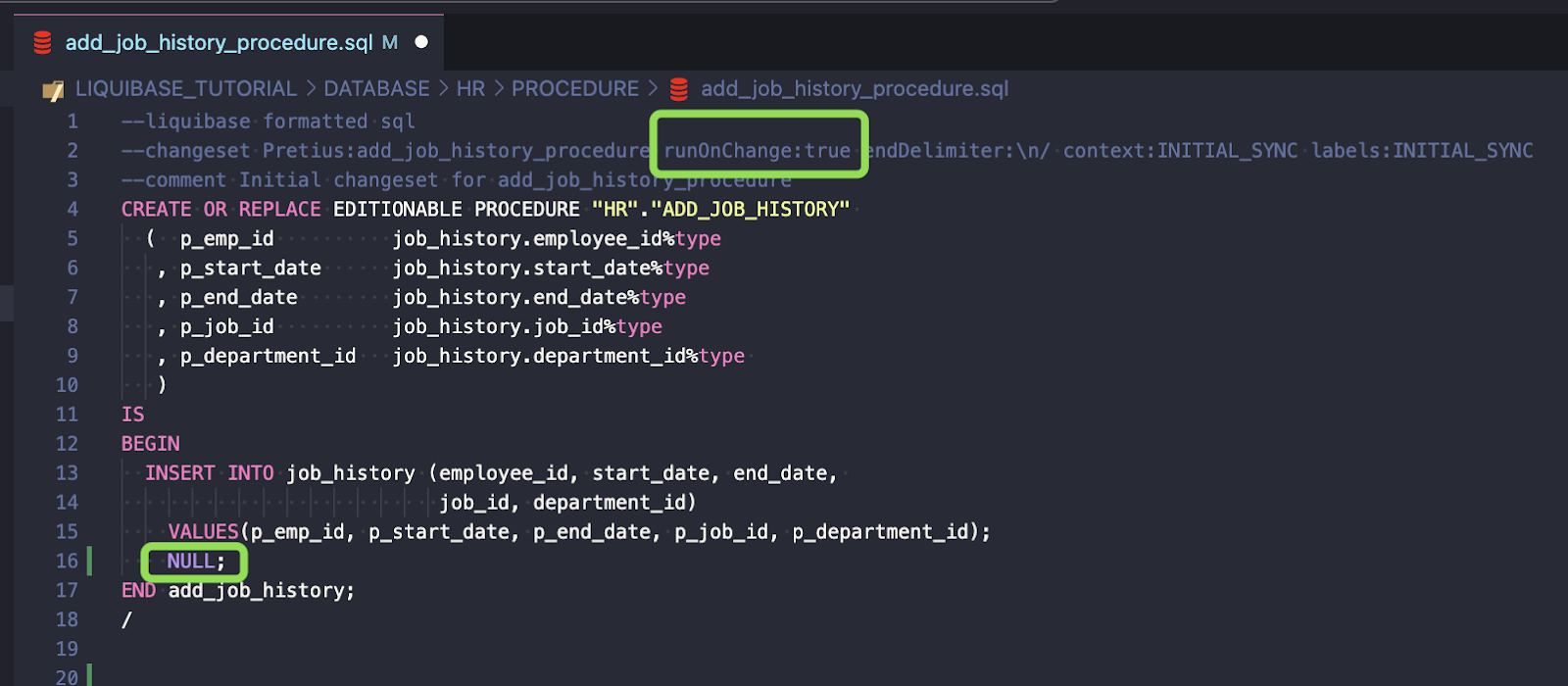
Making changes at DEV using Liquibase
Now, let’s start making and tracking changes in our database. To make things simple, I’ll specify the requirements and steps you need to follow to implement each one.
My examples will show changes made by two developers, RAFAL and JOHN, who work with the same DEV database. They are also using GIT and Visual Studio Code.
NO CHANGES are done directly in the database. Everything must go through SQL files and Liquibase.
This is a rule that all developers must obey. Otherwise, using Liquibase doesn’t make sense.
Requirement JIRA-1 (assigned to developer RAFAL)
Add a new table "CUSTOMERS" and Foreign Key, to the existing COUNTRIES table
At this moment, the application has version_1
Jira task number is JIRA-1
Now, let’s go through the necessary steps.
Create a new GIT branch JIRA-1 based on the DEV branch
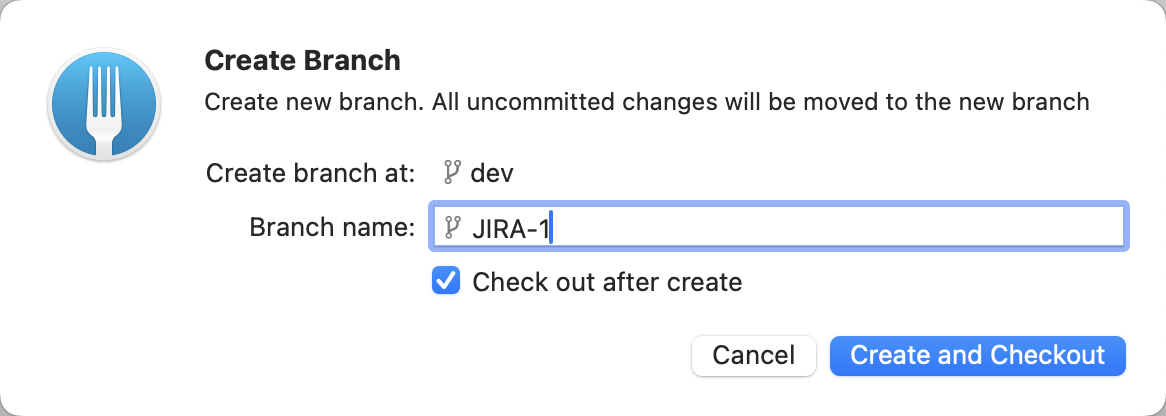
Create a table
Steps:
Create a new file DATABASE/HR/TABLE/customers.sql
Add Liquibase syntax and unique changeset values – ID and author
Add DDL code
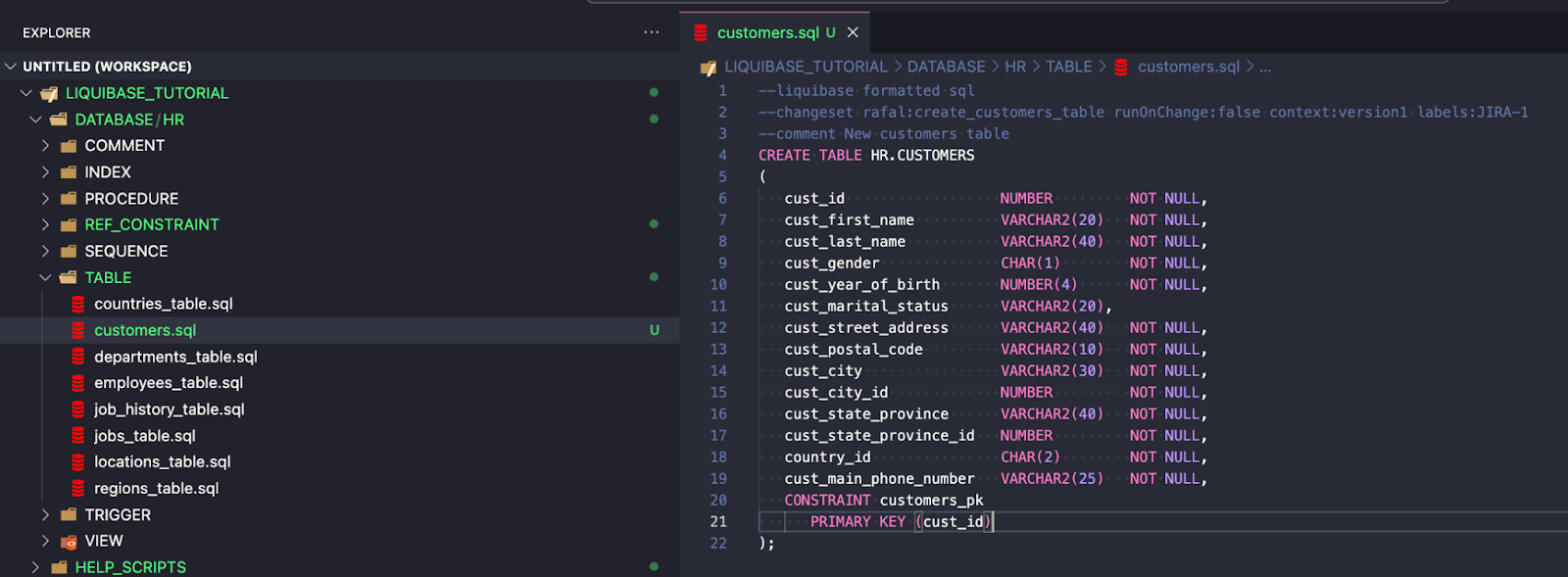
Legend:
rafal – authorId.
create_customers_table – changeset ID.
runOnChange:false – this parameter is an option, and the default value is false (it means you don’t need to write it). Changeset with runOnChange:false is a type of change that can be executed only once. Read more about this parameter here.
context – an optional parameter for more detailed information about executed changesets. Gives more control over changes. Context value should be written to DATABASECHANGELOG.CONTEXT column. More about contexts here.
labels – an optional parameter, similar to contexts written to the DATABASECHANGELOG.LABELS column. More in Liquibase documentation.
--liquibase formatted sql
--changeset rafal:create_customers_table runOnChange:false context:version1 labels:JIRA-1
--comment New customers table
CREATE TABLE HR.CUSTOMERS
(
cust_id NUMBER NOT NULL,
cust_first_name VARCHAR2(20) NOT NULL,
cust_last_name VARCHAR2(40) NOT NULL,
cust_gender CHAR(1) NOT NULL,
cust_year_of_birth NUMBER(4) NOT NULL,
cust_marital_status VARCHAR2(20),
cust_street_address VARCHAR2(40) NOT NULL,
cust_postal_code VARCHAR2(10) NOT NULL,
cust_city VARCHAR2(30) NOT NULL,
cust_city_id NUMBER NOT NULL,
cust_state_province VARCHAR2(40) NOT NULL,
cust_state_province_id NUMBER NOT NULL,
country_id CHAR(2) NOT NULL,
cust_main_phone_number VARCHAR2(25) NOT NULL,
CONSTRAINT customers_pk
PRIMARY KEY (cust_id)
);
Create a Foreign Key
Steps:
Create a new file DATABASE/HR/FOREIGN_KEY/customers_country_fk.sql
Add Liquibase syntax and unique changeset values – ID and author
Add DDL code
--liquibase formatted sql
--changeset rafal:customers_country_fk context:version1 labels:JIRA-1
--comment Foreign key customers ->countries
alter table customers add CONSTRAINT customers_country_fk FOREIGN KEY (country_id) REFERENCES countries (country_id);
UPDATE-SQL
To be clear, neither the CUSTOMERS table nor the Foreign key currently exists in my DEV database. It’s just a code in my SQL files. I need to use the Liquibase UPDATE command explained earlier to deploy changes.
However, before executing the UPDATE command, it’s highly recommended that you run the UPDATE-SQL command first. This command generates an SQL file that shows you what would be executed if you ran the UPDATE command later.
liquibase --defaults-file=dev.liquibase.properties update-sql --label-filter=JIRA-1
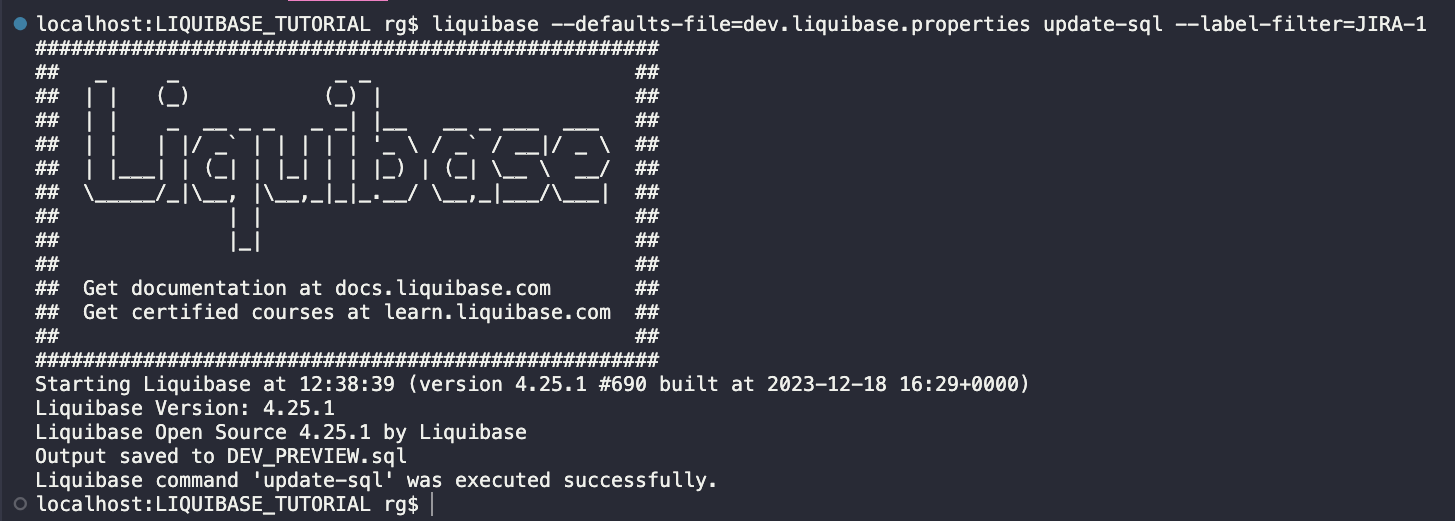
Legend:
defaults-file – this parameter is used to define my connection file
label-filter – optional parameter to execute only changes with specified labels. It’s really useful, especially if more than one developer is working on the same database. Why should you use --label-filter?
Let’s assume developer RAFAL is working on the GIT branch JIRA-1 and developer JOHN is working on the GIT branch JIRA-2 at the same time.
JOHN already executed the update command from his branch JIRA-2, where he changed procedure add_job_history_procedure.sql
Right after JOHN, RAFAL will execute the UPDATE command without specifying --label-filter.
What will be deployed to DEV? All Rafal’s changes (CUSTOMER table +FK) and add_job_history_procedure will be overwritten with a version from RAFAL’sJIRA-1 branch. That will happen because RAFAL doesn’t have JOHN’s changed version of the procedure in his repository yet.
If RAFAL uses the --labels-filter, only his changes will be deployed.
DEV_PREVIEW.sql – this is the default output-file name I defined in dev.liquibase.properties
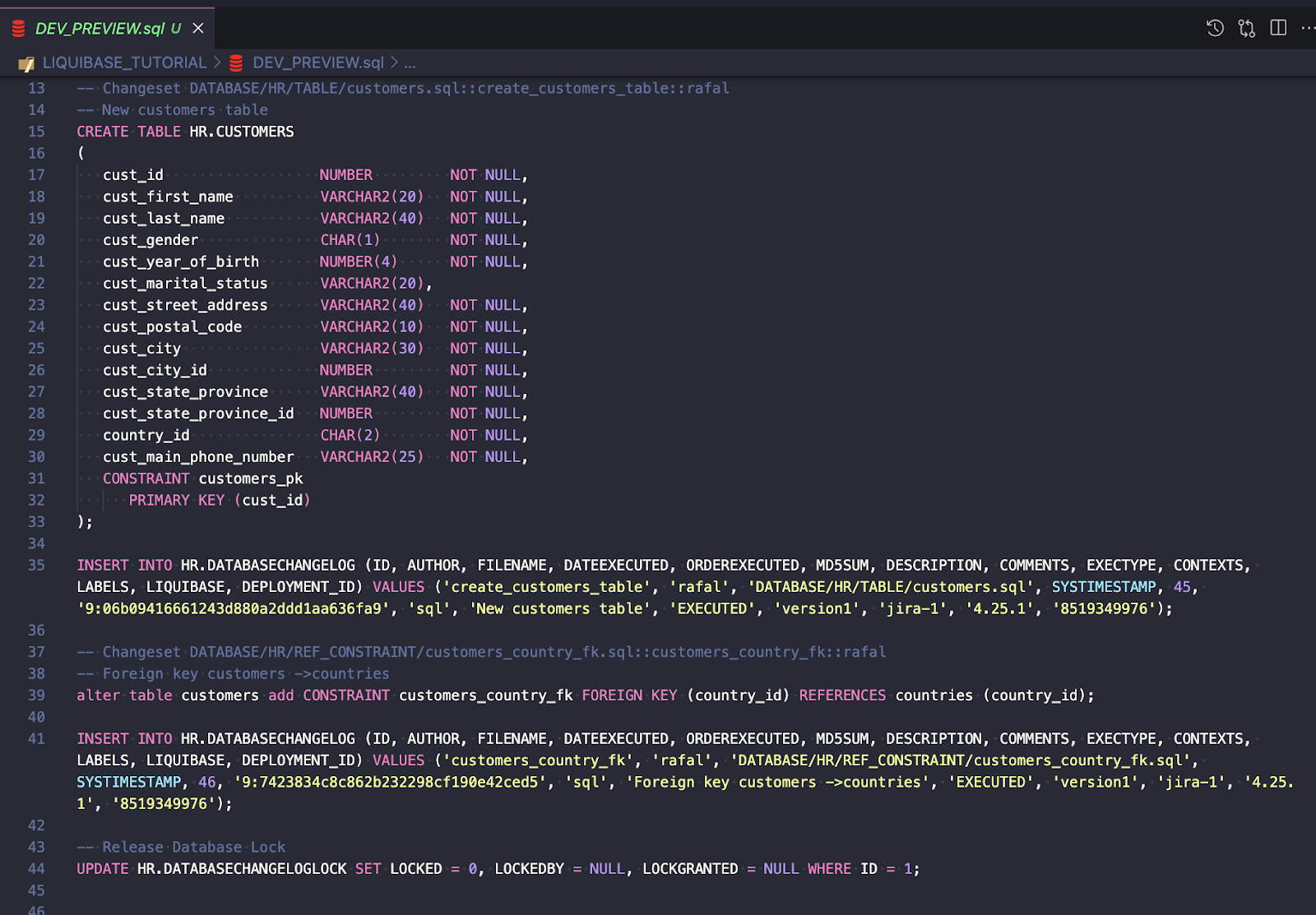
The script looks good (the full script is available here), so I’m ready to deploy my changes using the UPDATE command.
UPDATE
liquibase --defaults-file=dev.liquibase.properties update --label-filter=JIRA-1
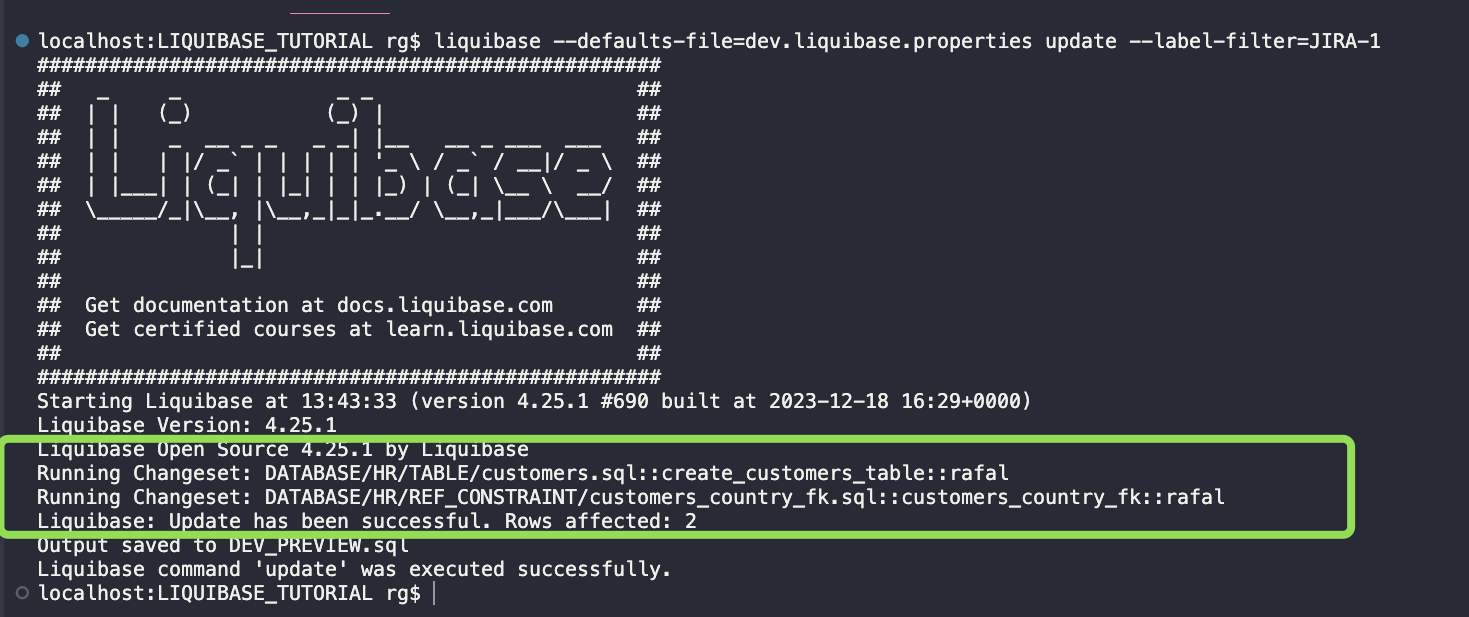
Nice info in the DEV_PREVIEW.sql file.
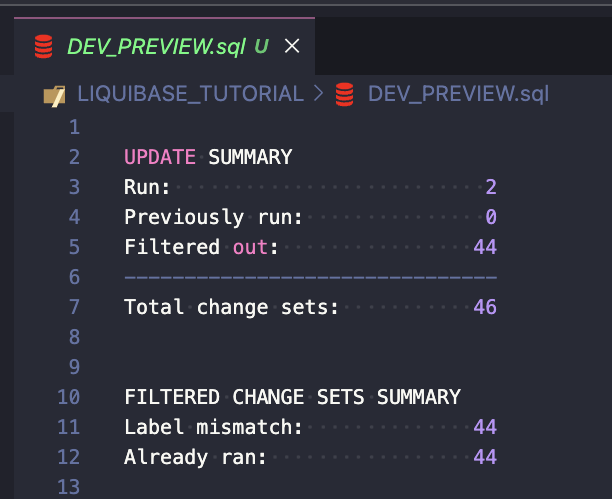
And two new rows were inserted into the DATABASECHANGELOG table:

There are also two new columns:

Merge into DEV branch
My changes regarding JIRA-1 task were successfully deployed to the DEV database. I can merge my changes to the DEV branch.
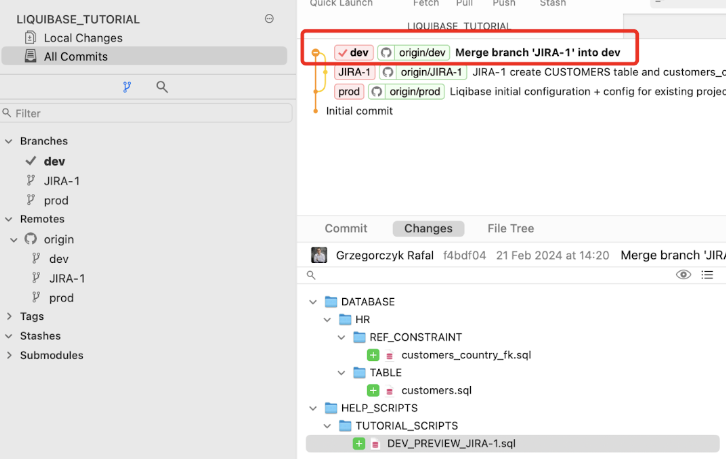
Requirement JIRA-2 (assigned to developer JOHN)
Create a new package COE_DOM_HELPER
Change existing joins in EMP_DETAILS_VIEW from old-fashioned Oracle joins to ANSI joins
At this moment, the application has version_1
Jira task number is JIRA-2
Let’s go through the steps.
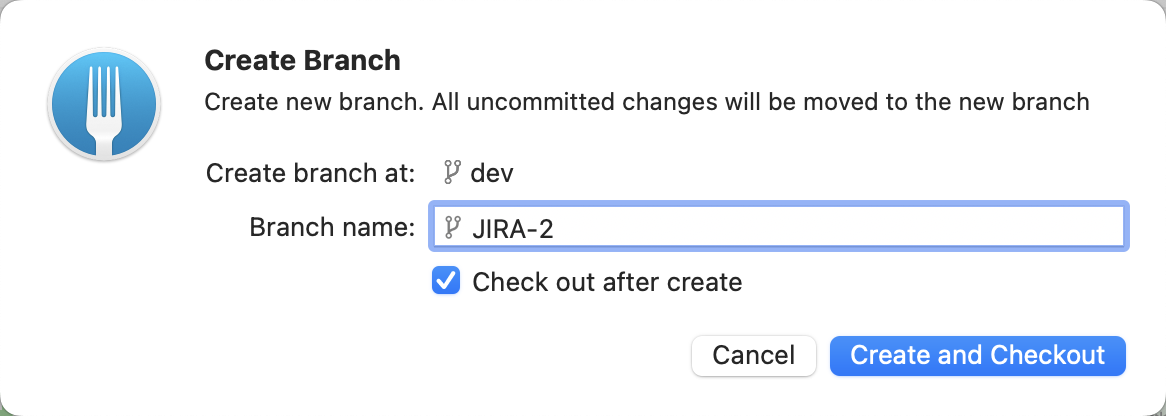
Create a new GIT branch JIRA-2
Create a new package spec and body
Steps:
- First, create two new folders
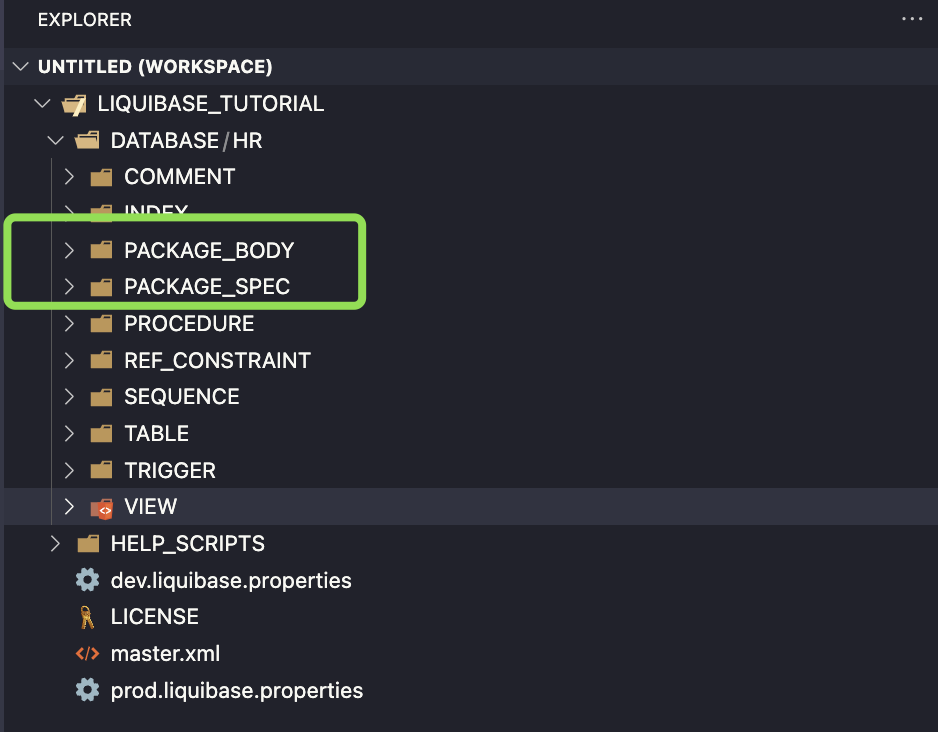
- Include those folders in master.xml file
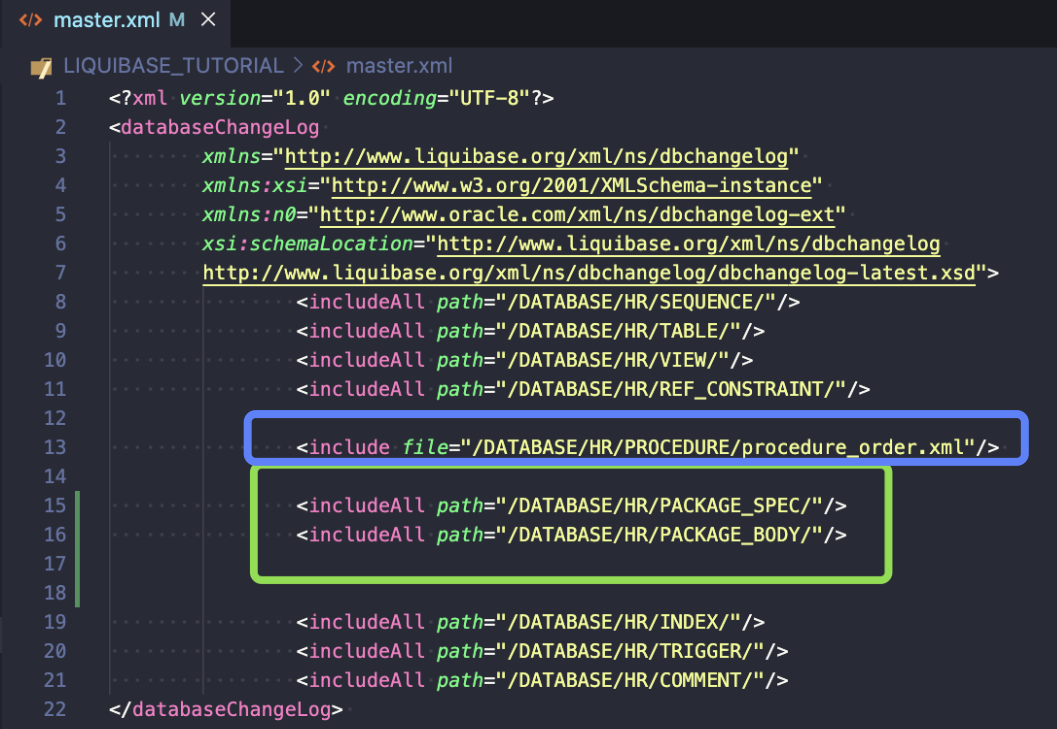
I used includeAll which means that all SQL files I create in those folders will be executed alphabetically. If you want more control use the include file tag, as I did in the line above (blue box).
- Create files with code, separate for package spec and package body
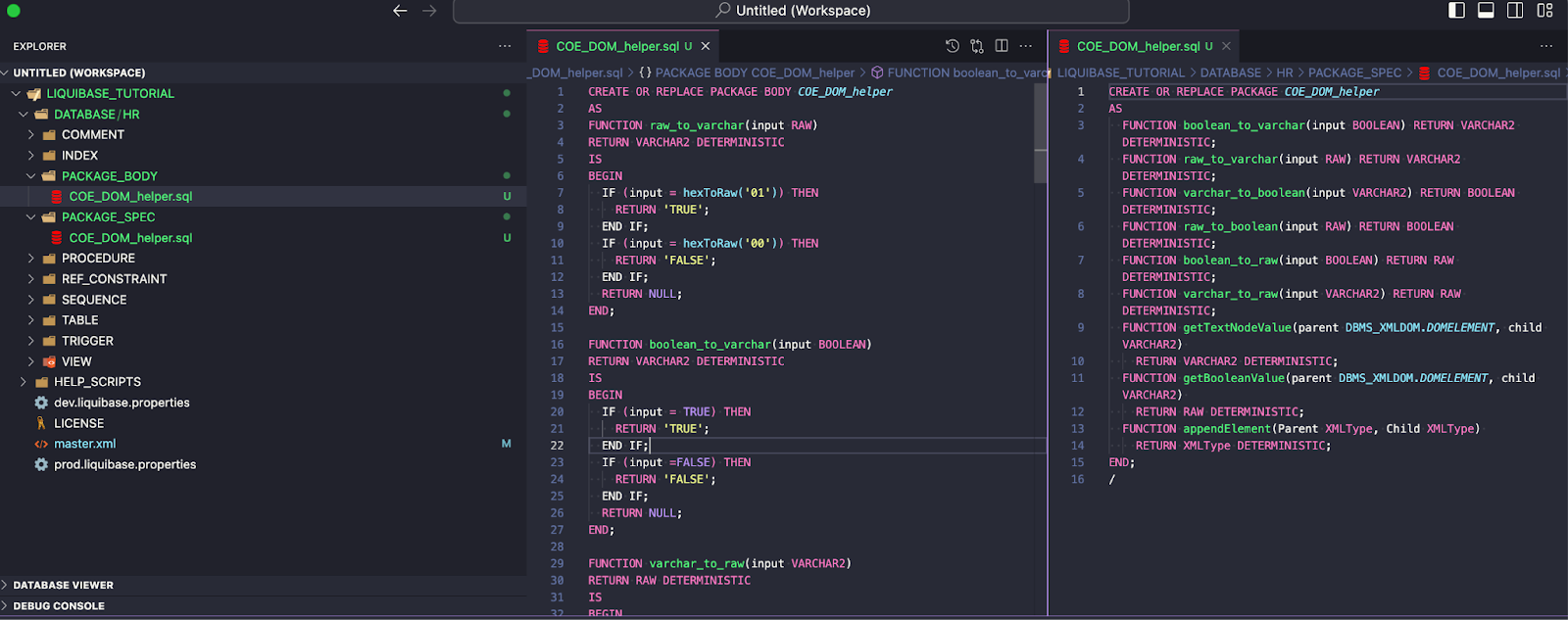
- Add Liquibase syntax to both files
Lines to add to the package body:
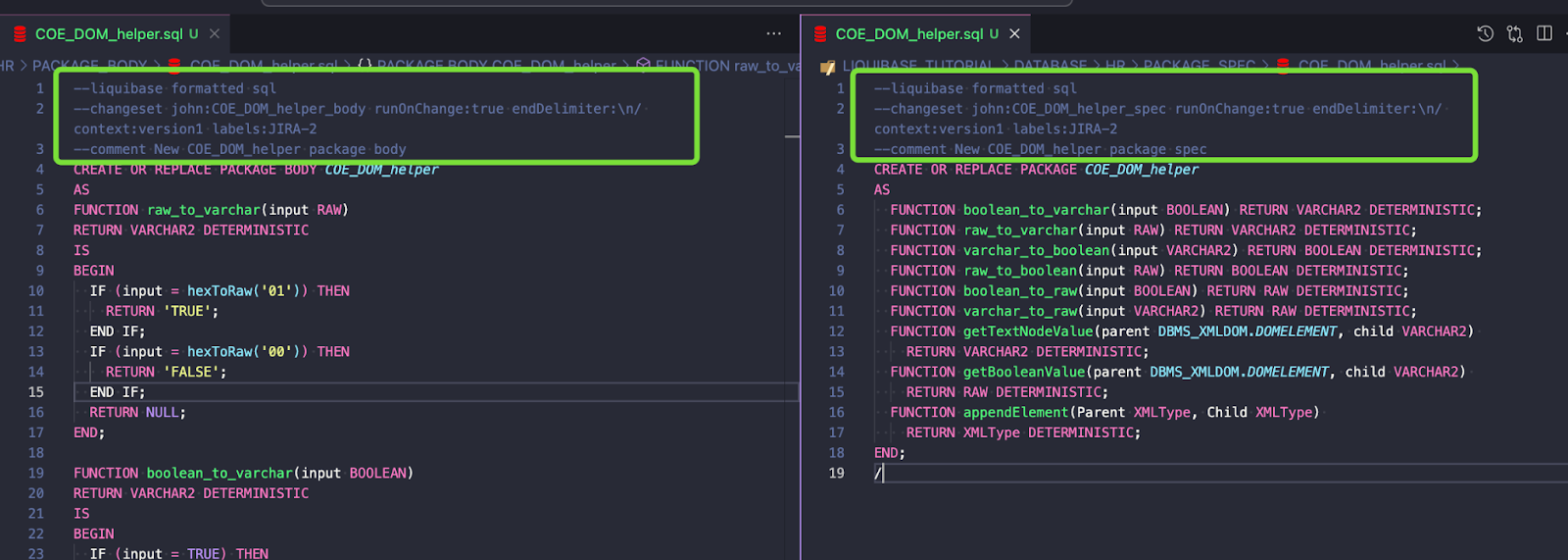
--liquibase formatted sql
--changeset john:COE_DOM_helper_body runOnChange:true endDelimiter:\n/ context:version1 labels:JIRA-2
--comment New COE_DOM_helper package body
Add these lines to package spec:
--liquibase formatted sql
--changeset john:COE_DOM_helper_spec runOnChange:true endDelimiter:\n/ context:version1 labels:JIRA-2
--comment New COE_DOM_helper package spec
Legend:
runOnChange – for all objects that are replaceable (packages, views, procedures), this parameter should be set to true. It allows you to change the code in the existing changeset and re-run it as many times as needed.
endDelimiter – an attribute that lets you specify a delimiter to separate raw SQL statements in your changesets. \n/ states for delimiter “/”
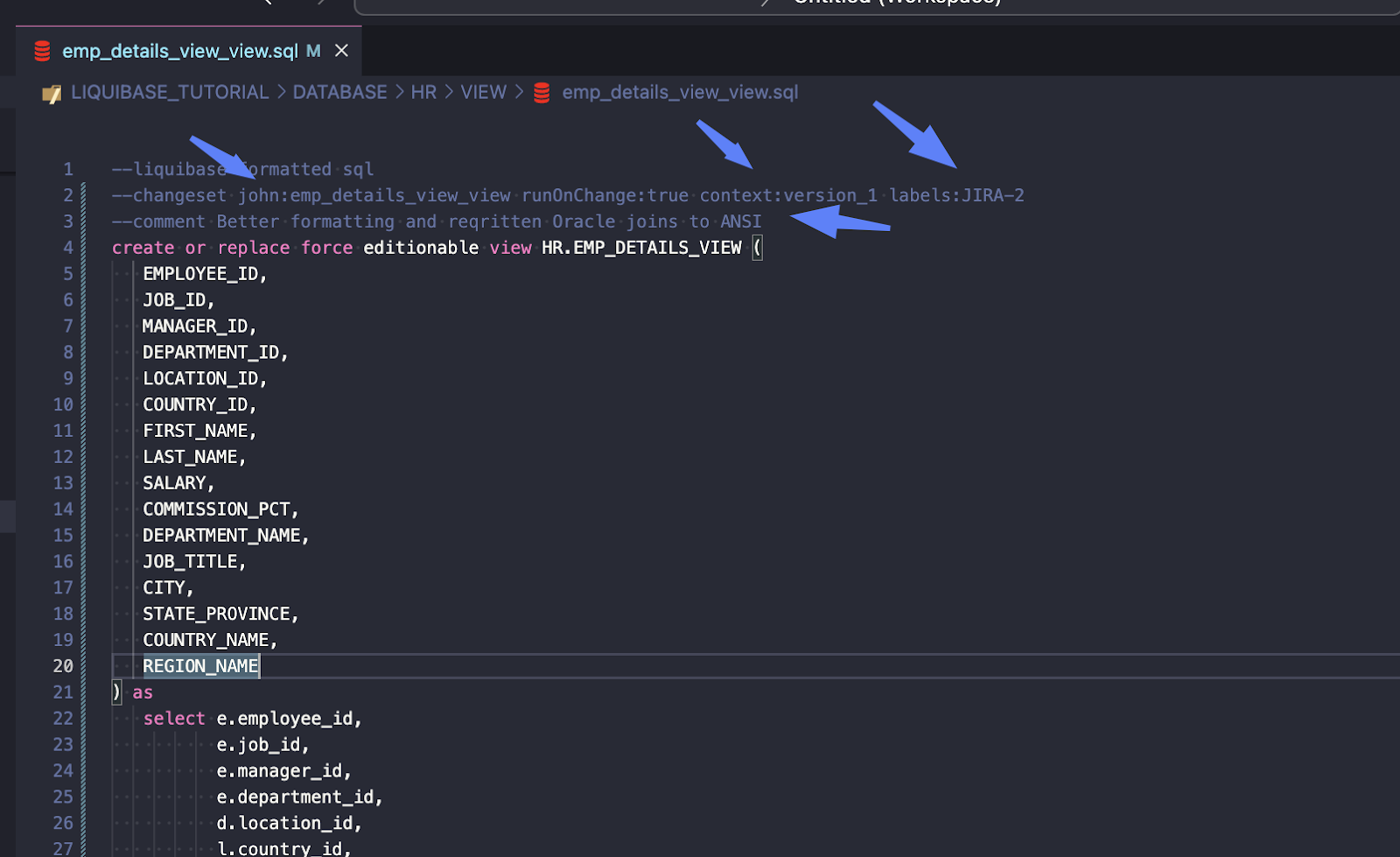
Change VIEW
Steps:
Change those values in the changeset plus do the refactoring, and change from old-fashioned Oracle joins to ANSI joins
Changeset has runOnChange:true, so Liquibase will recalculate the checksum during execution and re-run this script
UPDATE-SQL
Preview what will be deployed via this command:
liquibase --defaults-file=dev.liquibase.properties update-sql --label-filter=JIRA-2
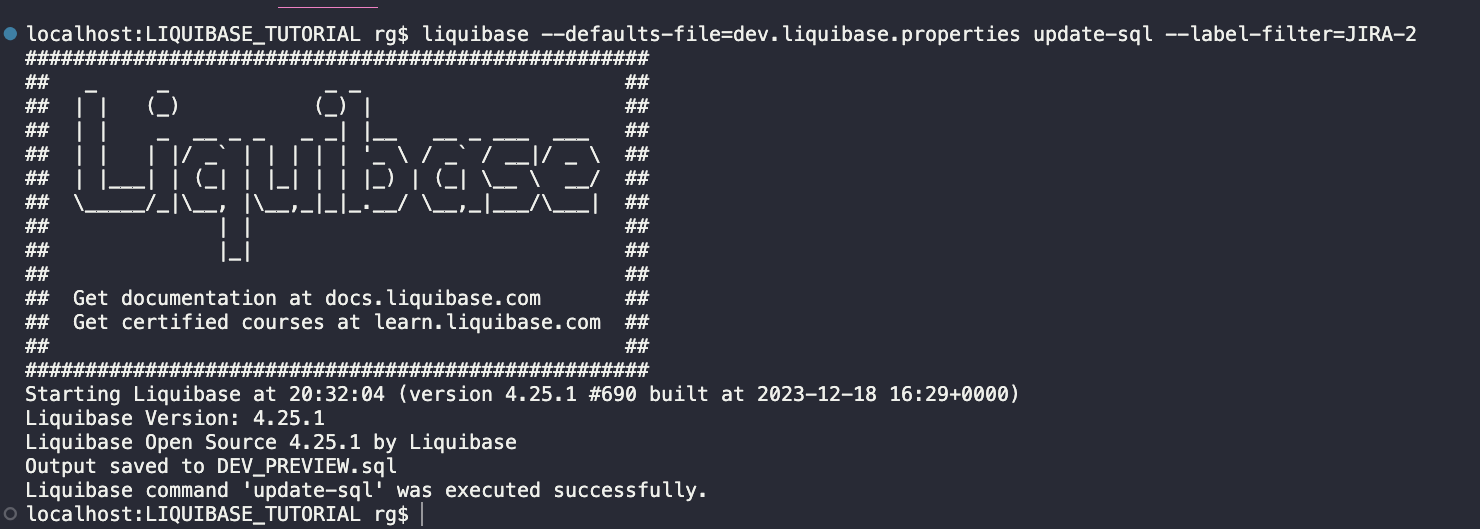
Looks good (preview the full file here).
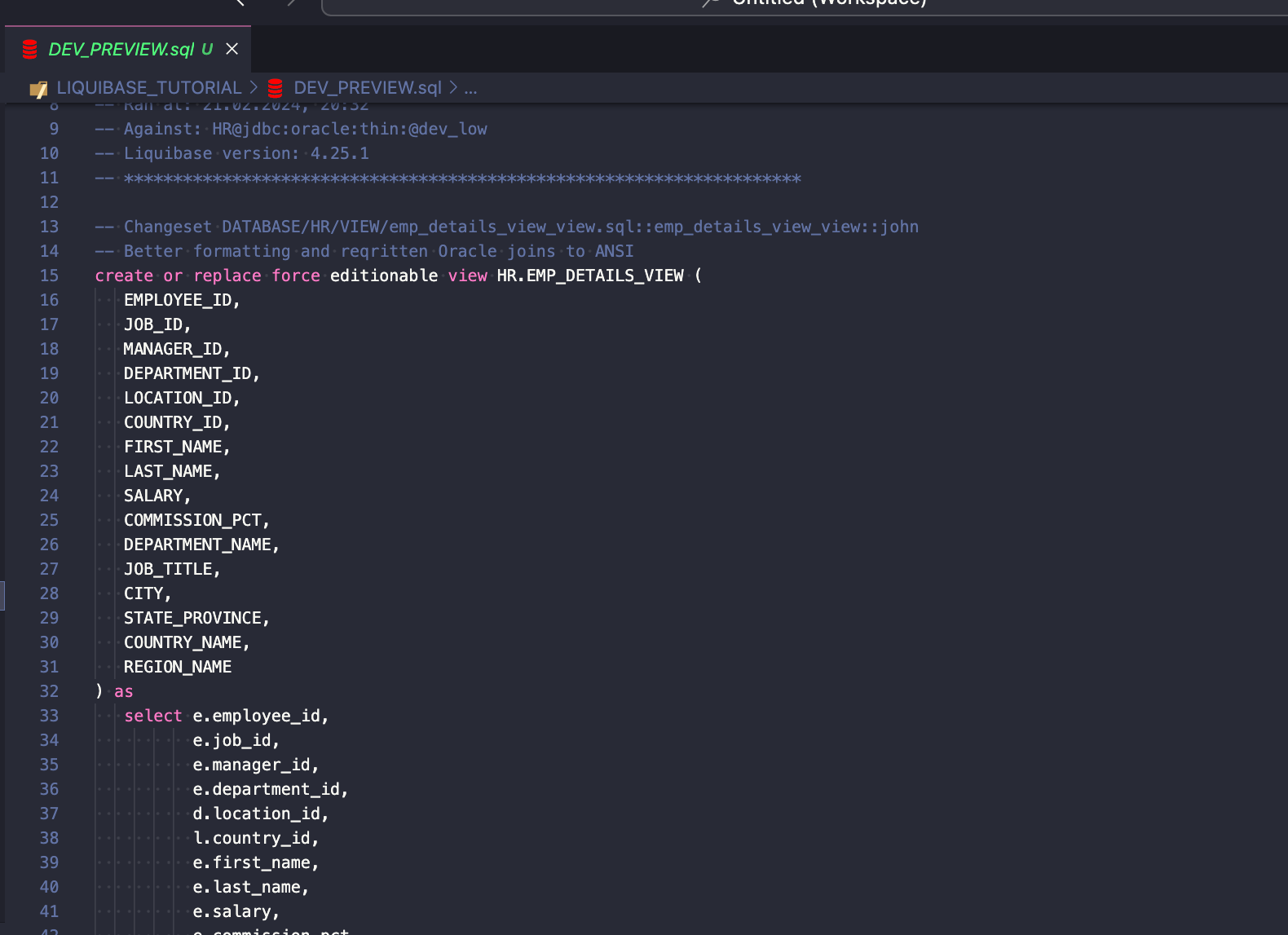
UPDATE
Execute Liquibase UPDATE command to deploy those 3 new changes:
liquibase --defaults-file=dev.liquibase.properties update --label-filter=JIRA-2
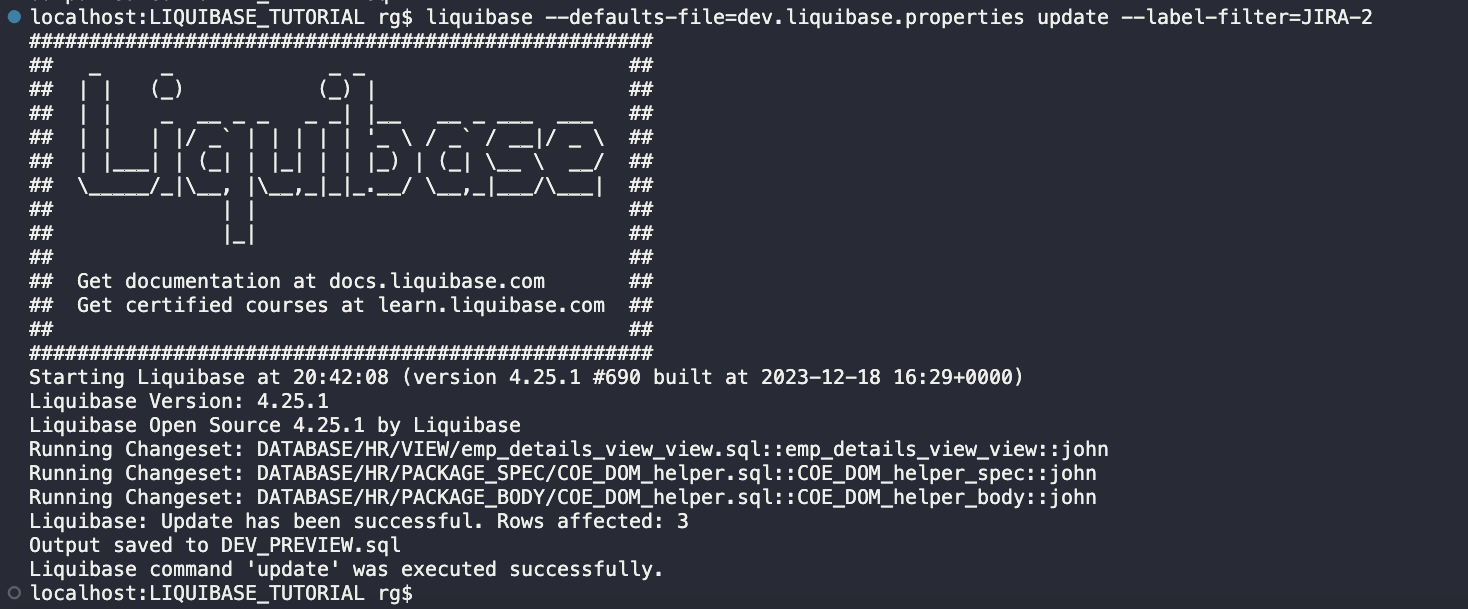
Changes were deployed to my DEV database, and there are 3 new rows in the DATABASECHANGELOG table:
Merge into DEV branch
Requirement JIRA-3 (assigned to developer: RAFAL)
- Create a changeset that will compile invalid HR schema objects before and after execution of other database changes
Create a new table PARAMETERS and insert values. Data to insert is different for DEV and PROD environments
Create a new GIT branch JIRA-3
Execute scripts / anonymous blocks using Liquibase (compile schema)
Steps:
- To run something before and after other changes, create /pre-scripts/ and /post-scripts/ folders
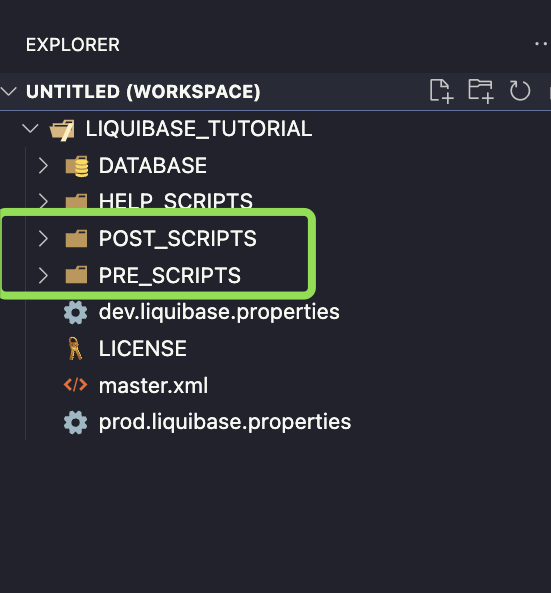
- Include new files in master.xml
- Those files will take care of the order of your pre and post-scripts. For the purposes of this example, I don’t want to use includeAll as I want to have full control. I’m using include file instead)
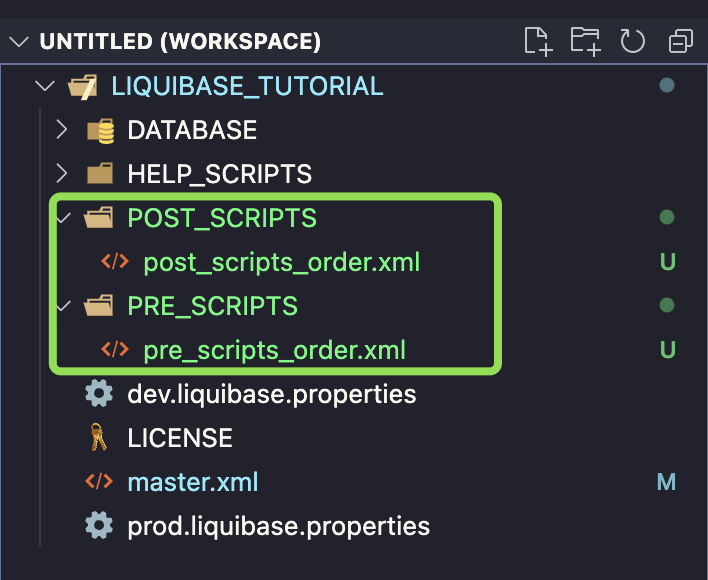
- Write a script that will compile your HR schema before and after execution of other Liquibase changesets
For PRE_SCRIPTS:
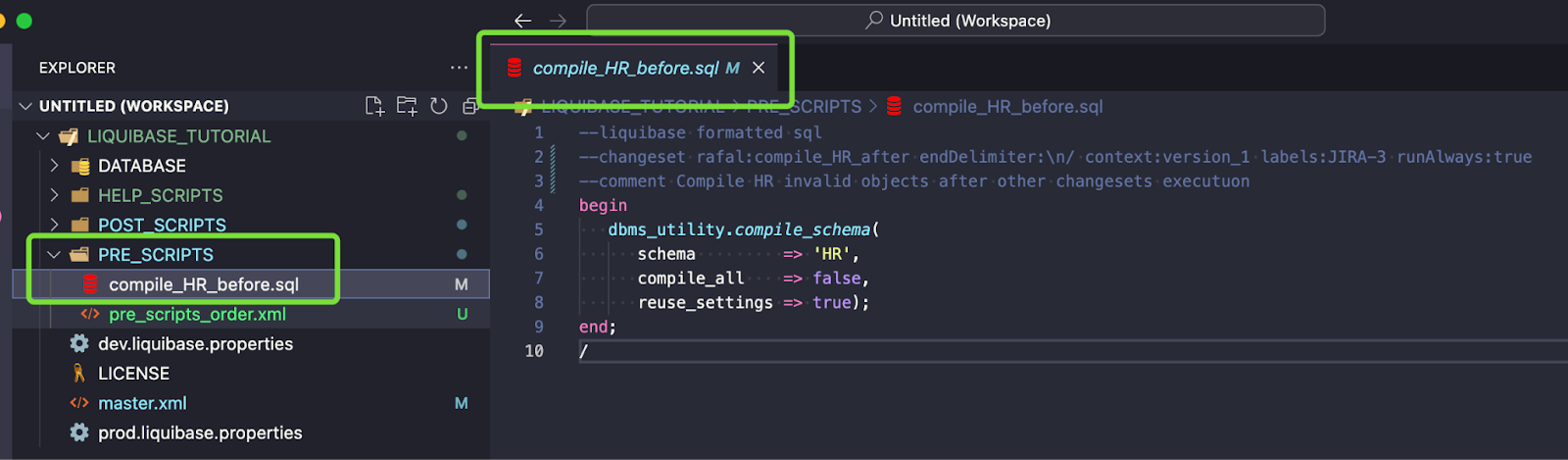
Include this file in pre_scripts_order.xml
Full changeset code:
--liquibase formatted sql --changeset rafal:compile_HR_after endDelimiter:\n/ context:version_1 labels:JIRA-3 runAlways:true --comment Compile HR invalid objects after other changesets executuon begin dbms_utility.compile_schema( schema => 'HR', compile_all => false, reuse_settings => true); end; /There’s something new in the above syntax – runAlways:true. Thanks to this parameter, Liquibase will execute this changeset every time you will run the UPDATE command.
- Repeat the above steps for POST_SCRIPTS
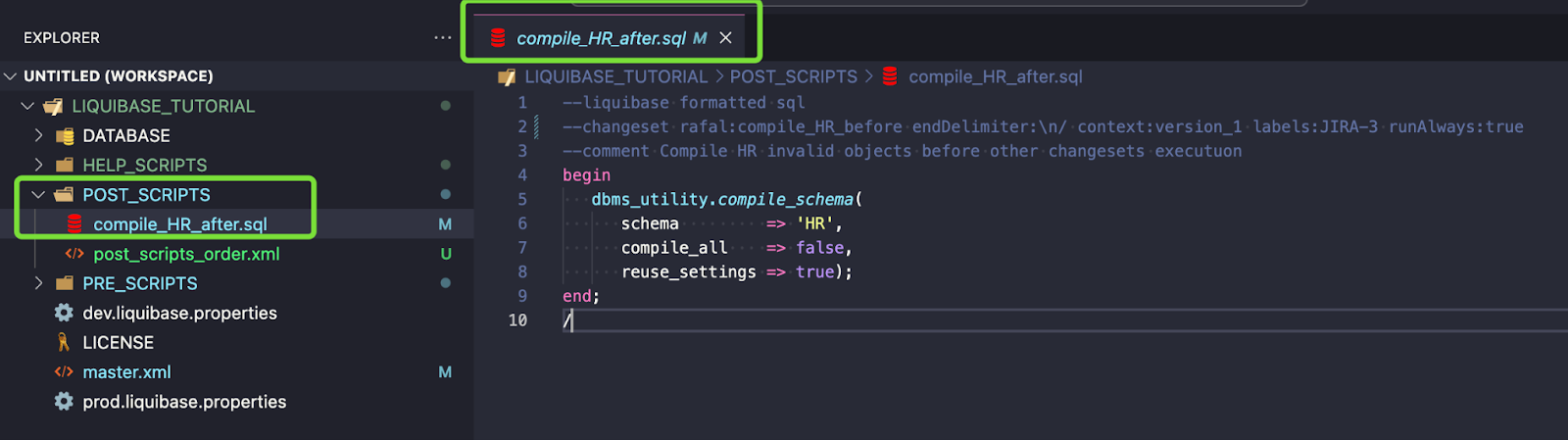
Full changeset code:
--liquibase formatted sql
--changeset rafal:compile_HR_before endDelimiter:\n/ context:version_1 labels:JIRA-3 runAlways:true
--comment Compile HR invalid objects before other changesets executuon
begin
dbms_utility.compile_schema(
schema => 'HR',
compile_all => false,
reuse_settings => true);
end;
/
Create a new table PARAMETERS
Steps:
- Create a new file DATABASE/HR/TABLE/parameters.sql and a changeset
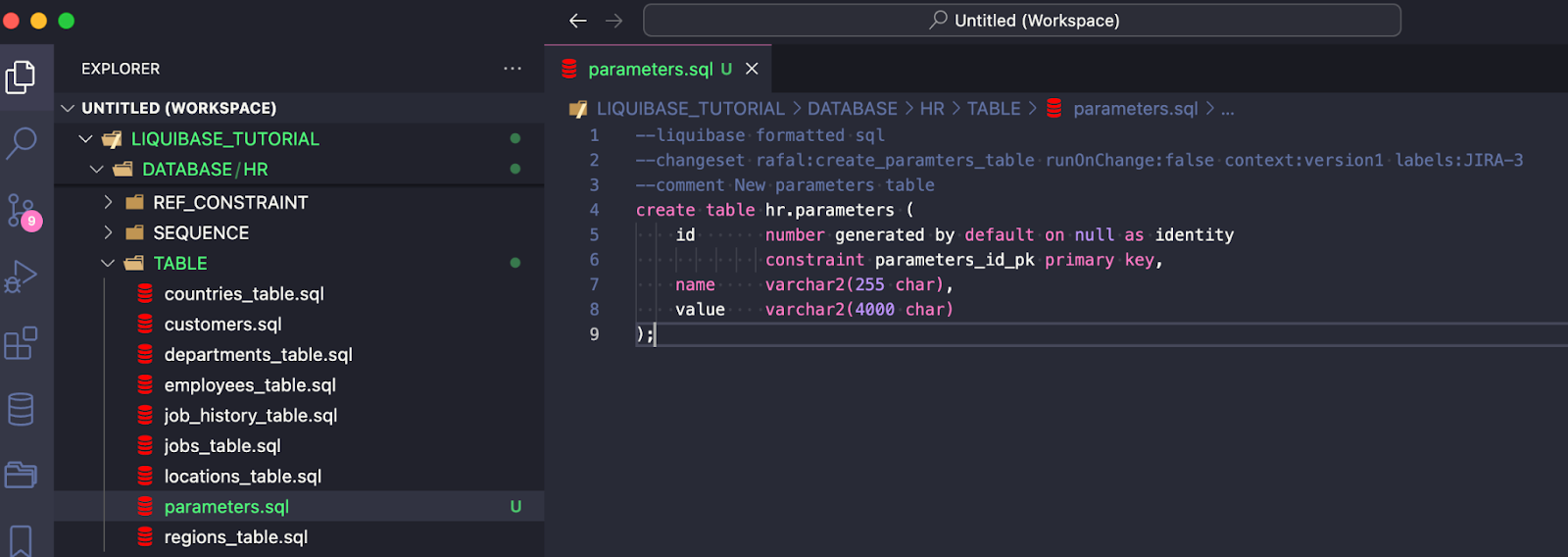
--liquibase formatted sql
--changeset rafal:create_paramters_table runOnChange:false context:version1 labels:JIRA-3
--comment New parameters table
create table hr.parameters (
id number generated by default on null as identity
constraint parameters_id_pk primary key,
name varchar2(255 char),
value varchar2(4000 char)
);
Use preConditions to insert values specific to DEV or PROD environment
Steps:
Create a new folder POST_SCRIPTS/DML
DML code should be executed at the end to be sure that the object will exist (PARAMETERS table will be created earlier)
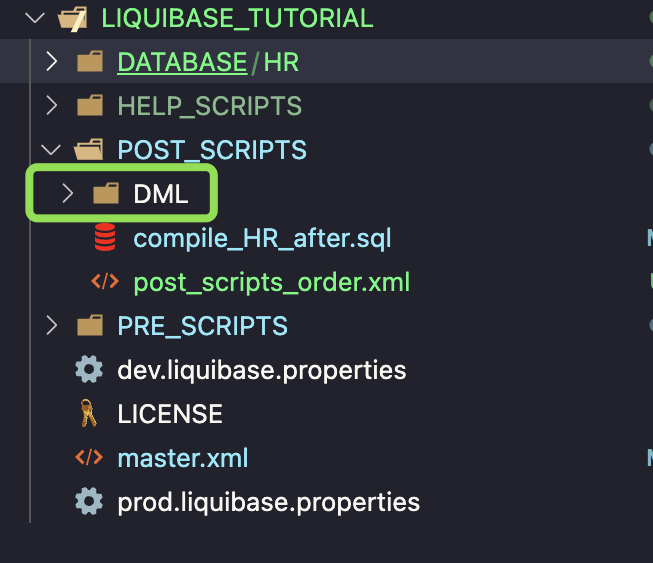
Create a new changelog dml_order.xml that will be used to control the order of DML execution. It’s essential to order DMLs carefully, as tables may have dependencies
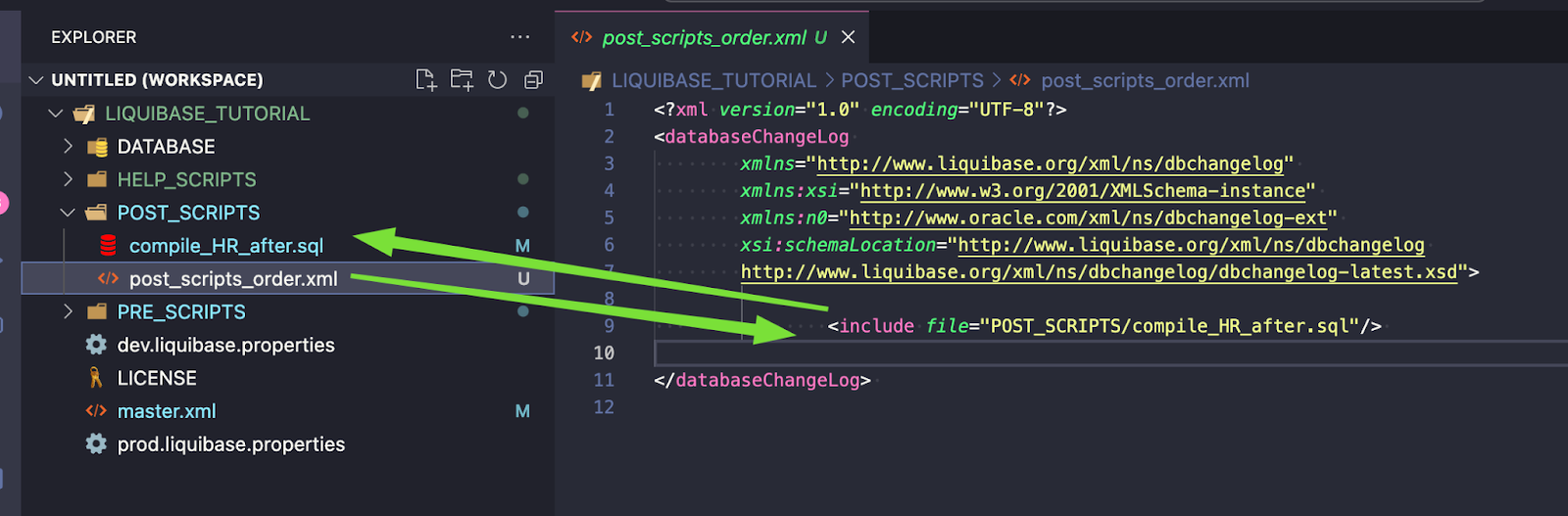
Add path for dml_order.xml to the post_scripts_order.xml file
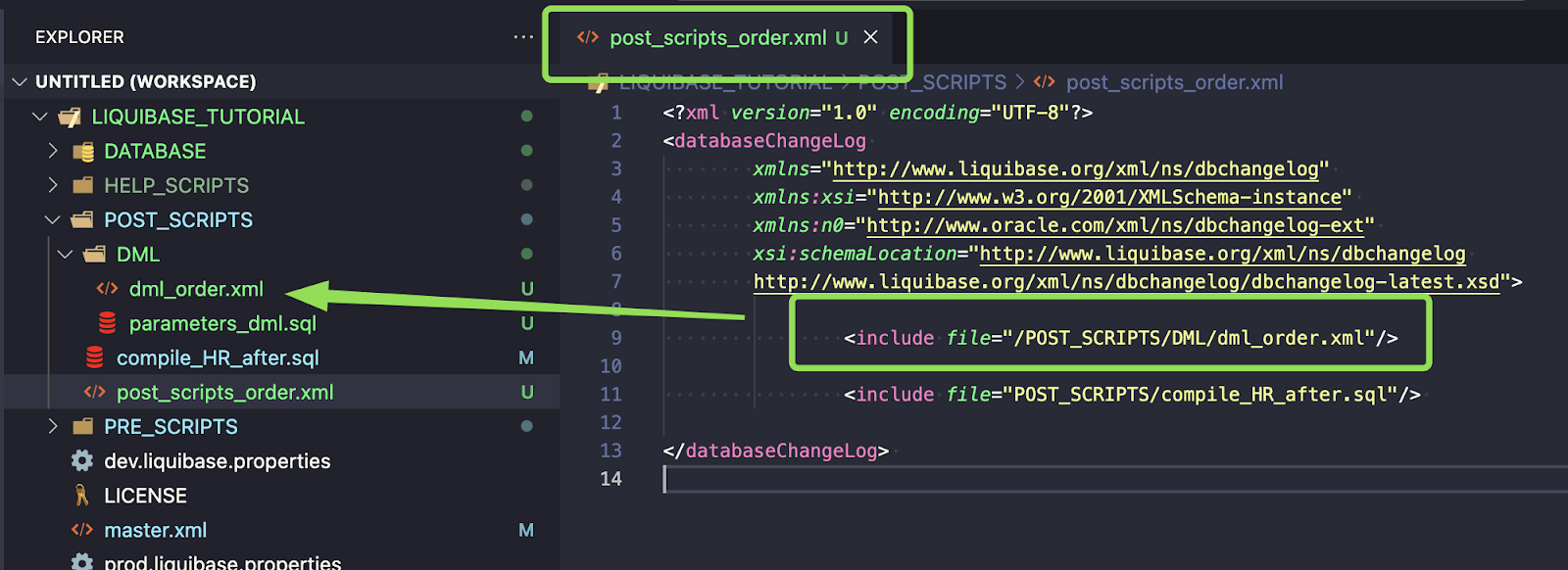
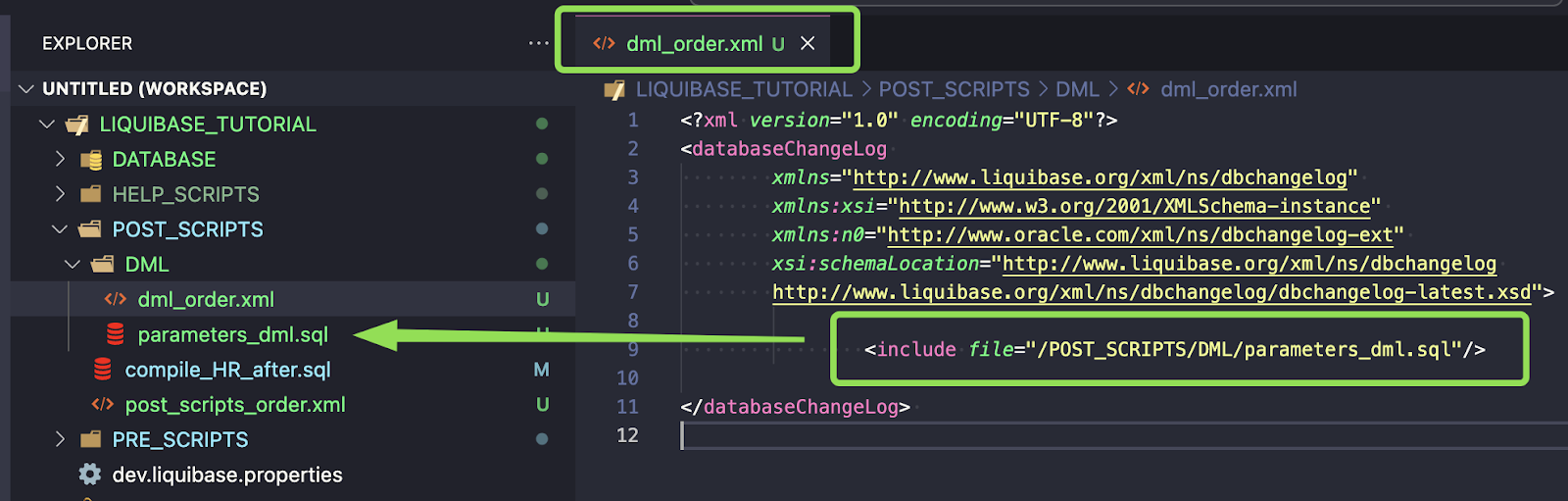
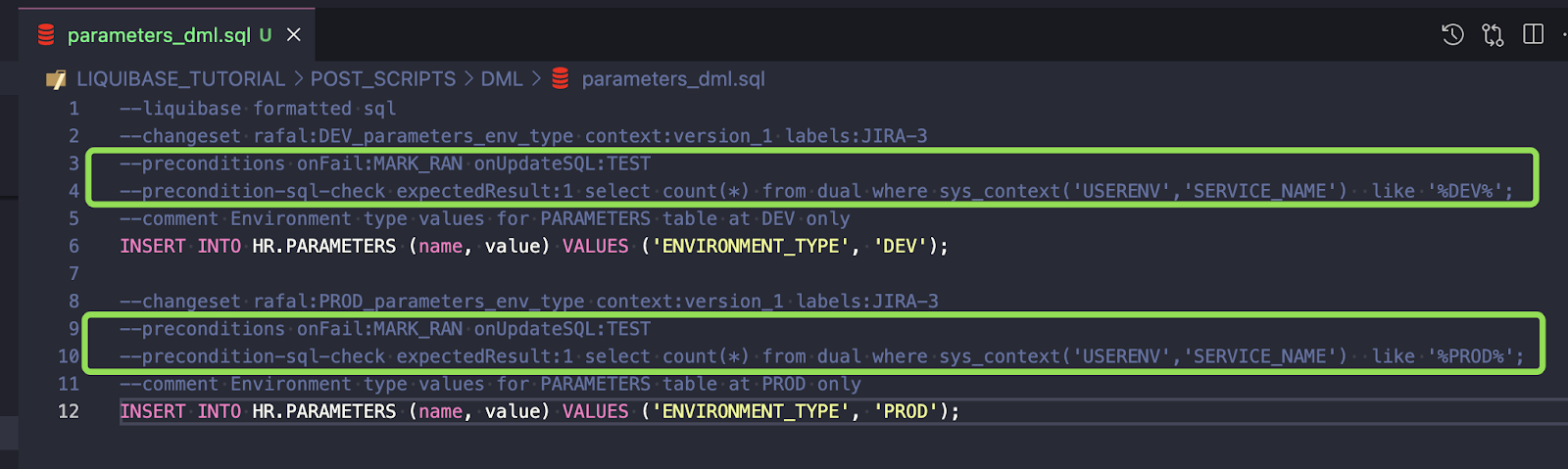
Create a new file POST_SCRIPTS/DML/parameters_dml.sql. This file will be used for all DML code to PARAMETERS table only
Add a path for parameters_dml.sql to the dml_order.xml changelog
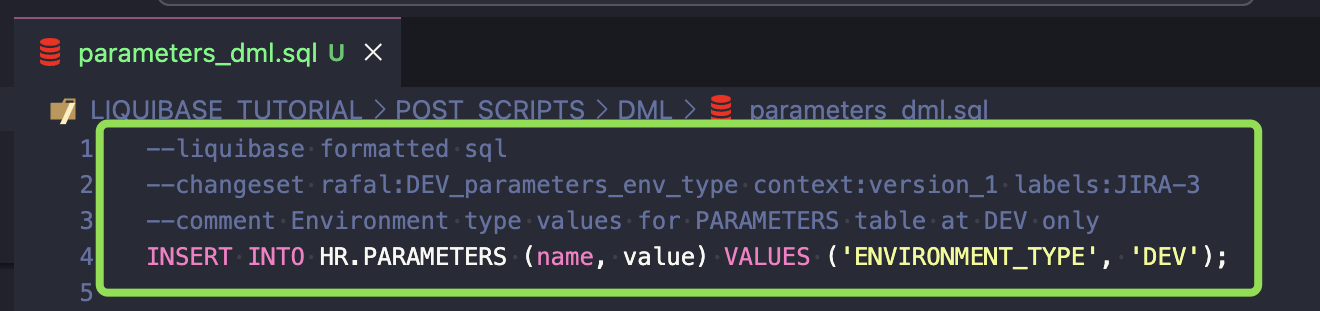
- Create DML code to insert values into PARAMETERS. This code should be executed in the DEV environment only
- Create similar code to be inserted into PROD only
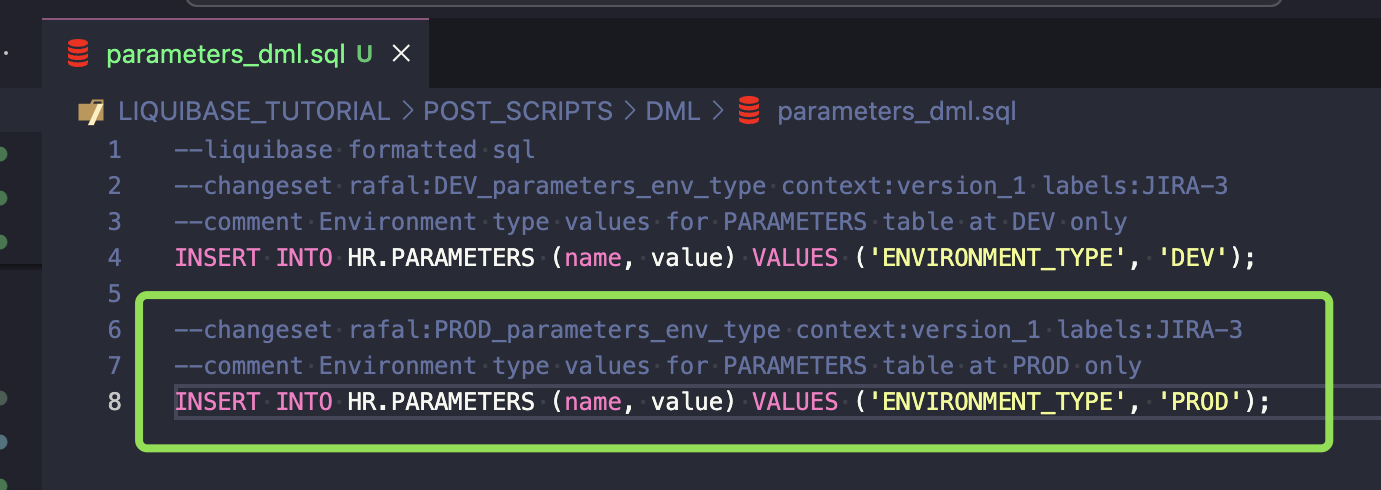
However, this will not be enough because changesets defined this way will be executed in every environment. You’ll need to use Liquibase preConditions.
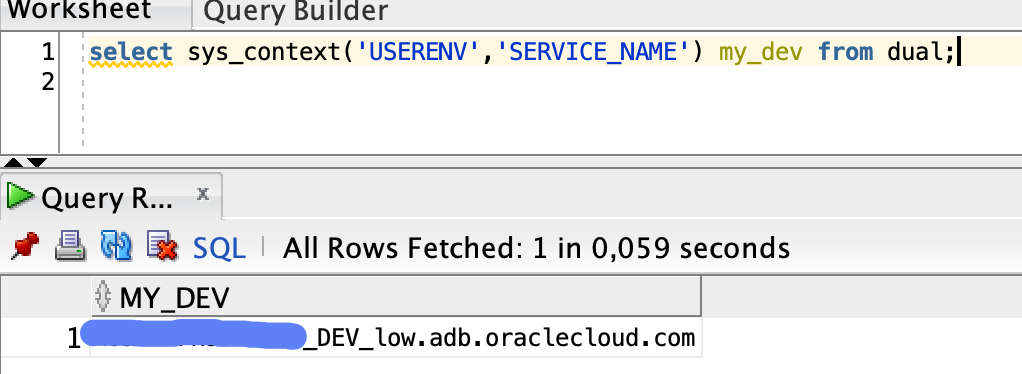
How will you know if your Autonomous Database is DEV or PROD? Your service_name parameter will contain either DEV or PROD value. This query should be enough:
- Tweak your DML changesets so they will be executed only at DEV or PROD environments
UPDATE-SQL
Changes are prepared. Run UPDATE-SQL to check what will be executed at DEV:
liquibase --defaults-file=dev.liquibase.properties update-sql --label-filter=JIRA-3
My preview script is below and in the repo here, and all is as I expected. What will happen:
HR schema will be compiled
Table PARAMETERS will be created
Values into PARAMETERS will be inserted, but only those for DEV environment
For PROD values, one row will be inserted into the DATABASECHANGELOG table with a value for EXECTYPE column = MARK_RAN
HR schema will be compiled
Preview script:
-- Lock Database
UPDATE HR.DATABASECHANGELOGLOCK SET LOCKED = 1, LOCKEDBY = 'localhost (192.168.0.2)', LOCKGRANTED = SYSTIMESTAMP WHERE ID = 1 AND LOCKED = 0;
-- *********************************************************************
-- Update Database Script
-- *********************************************************************
-- Change Log: master.xml
-- Ran at: 22.02.2024, 15:08
-- Against: HR@jdbc:oracle:thin:@dev_low
-- Liquibase version: 4.25.1
-- *********************************************************************
-- Changeset PRE_SCRIPTS/compile_HR_before.sql::compile_HR_after::rafal
-- Compile HR invalid objects after other changesets executuon
begin
dbms_utility.compile_schema(
schema => 'HR',
compile_all => false,
reuse_settings => true);
end;
/
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('compile_HR_after', 'rafal', 'PRE_SCRIPTS/compile_HR_before.sql', SYSTIMESTAMP, 50, '9:84b226d042023ca9771041f4c887fd6a', 'sql', 'Compile HR invalid objects after other changesets executuon', 'EXECUTED', 'version_1', 'jira-3', '4.25.1', '8610923542');
-- Changeset DATABASE/HR/TABLE/parameters.sql::create_paramters_table::rafal
-- New parameters table
create table hr.parameters (
id number generated by default on null as identity
constraint parameters_id_pk primary key,
name varchar2(255 char),
value varchar2(4000 char)
);
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('create_paramters_table', 'rafal', 'DATABASE/HR/TABLE/parameters.sql', SYSTIMESTAMP, 51, '9:830a9f31b55e62c8fc4a3f8c2ee4e51c', 'sql', 'New parameters table', 'EXECUTED', 'version1', 'jira-3', '4.25.1', '8610923542');
-- Changeset POST_SCRIPTS/DML/parameters_dml.sql::DEV_parameters_env_type::rafal
-- Environment type values for PARAMETERS table at DEV only
INSERT INTO HR.PARAMETERS (name, value) VALUES ('ENVIRONMENT_TYPE', 'DEV');
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('DEV_parameters_env_type', 'rafal', 'POST_SCRIPTS/DML/parameters_dml.sql', SYSTIMESTAMP, 52, '9:d707b31273b18adf3fce32ddce9f1553', 'sql', 'Environment type values for PARAMETERS table at DEV only', 'EXECUTED', 'version_1', 'jira-3', '4.25.1', '8610923542');
-- Changeset POST_SCRIPTS/DML/parameters_dml.sql::PROD_parameters_env_type::rafal
-- Environment type values for PARAMETERS table at PROD only
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('PROD_parameters_env_type', 'rafal', 'POST_SCRIPTS/DML/parameters_dml.sql', SYSTIMESTAMP, 53, '9:7868f1d9e91fa2c43b86cd6f8bd5d698', 'sql', 'Environment type values for PARAMETERS table at PROD only', 'MARK_RAN', 'version_1', 'jira-3', '4.25.1', '8610923542');
-- Changeset POST_SCRIPTS/compile_HR_after.sql::compile_HR_before::rafal
-- Compile HR invalid objects before other changesets executuon
begin
dbms_utility.compile_schema(
schema => 'HR',
compile_all => false,
reuse_settings => true);
end;
/
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('compile_HR_before', 'rafal', 'POST_SCRIPTS/compile_HR_after.sql', SYSTIMESTAMP, 54, '9:84b226d042023ca9771041f4c887fd6a', 'sql', 'Compile HR invalid objects before other changesets executuon', 'EXECUTED', 'version_1', 'jira-3', '4.25.1', '8610923542');
-- Release Database Lock
UPDATE HR.DATABASECHANGELOGLOCK SET LOCKED = 0, LOCKEDBY = NULL, LOCKGRANTED = NULL WHERE ID = 1;
Execute changes to DEV
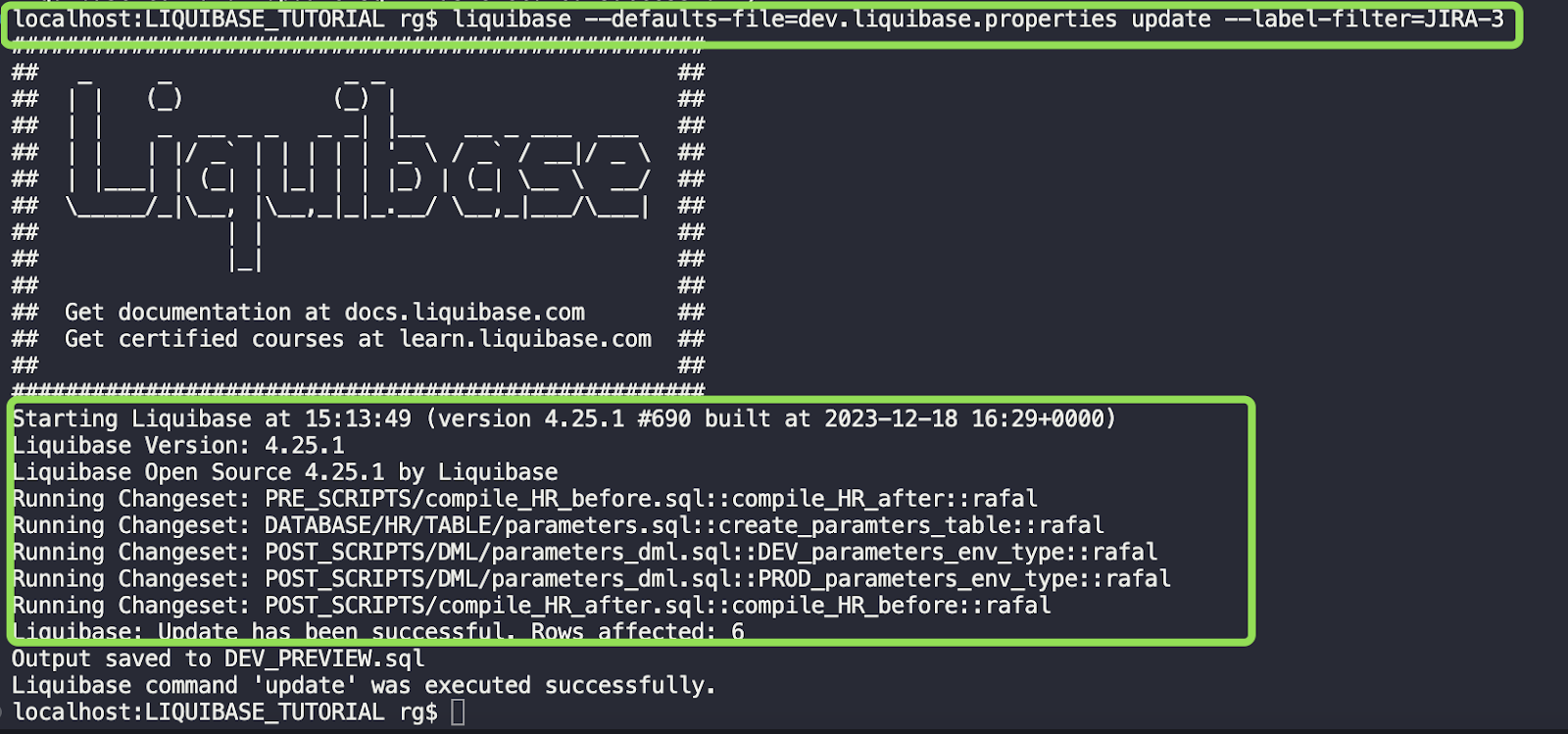
liquibase --defaults-file=dev.liquibase.properties update --label-filter=JIRA-3
All went well.

Only values for DEV are in the PARAMETERS table:
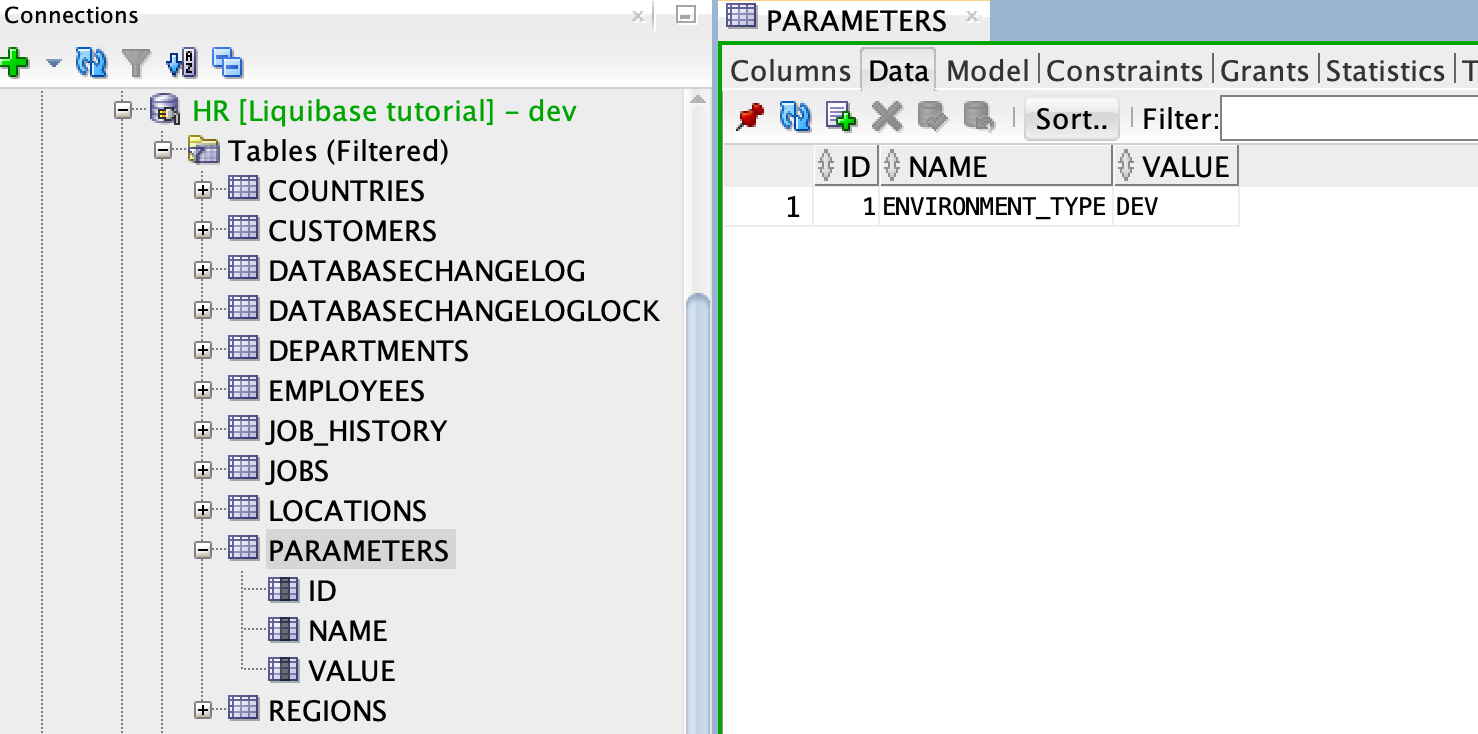
You can now merge the JIRA-3 branch into DEV.
Deployment to PROD
Finally, I will show you deploying changes made on DEV to another environment – in my case, it’s PROD, but it could also be UAT, PRE-PROD or any other. I’ll move changes from JIRA-1 and JIRA-2 first, and then follow with JIRA-3. You will only need to prepare proper liquibase.properties files with connections.
Deploy changes from JIRA-1 and JIRA-2 to PROD
In the previous part of this tutorial, RAFAL and JOHN developed some new features for version_1 of their application. They completed tasks JIRA-1, JIRA-2 and JIRA-3.
A new guy joins our team: Matt, a project manager. He says: “We need to deploy only changes from JIRA-1 and JIRA-2 tasks to PROD”.
I’m glad we used contexts and labels because it will be easier. Here’s how to do it.
GIT branching and switching
As you remember, we merged JIRA-1, JIRA-2, and JIRA-3 tasks to the DEV branch. So I can’t just merge DEV into PROD for deployment because it would include JIRA-3 changes that are not required.
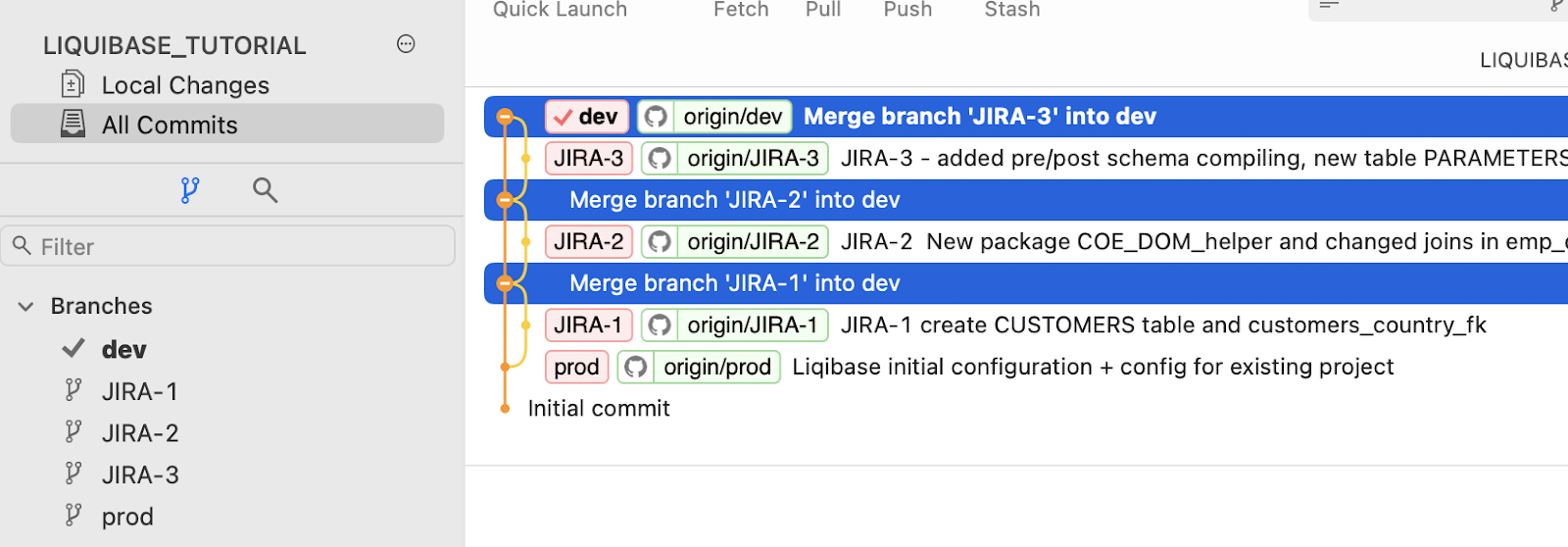
Here’s what we need to do:
- Create an additional branch and call it release_1.
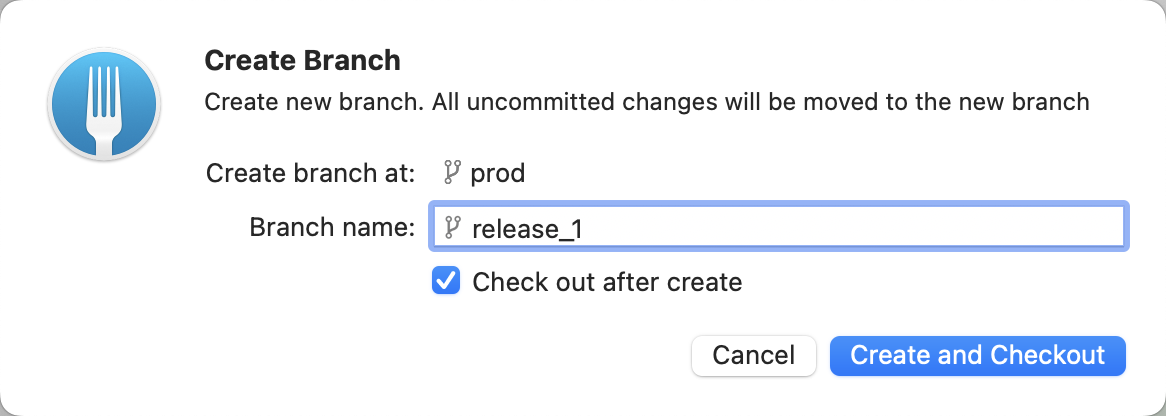
- Next, merge only branches JIRA-1 and JIRA-2 to the newly created branch release_1
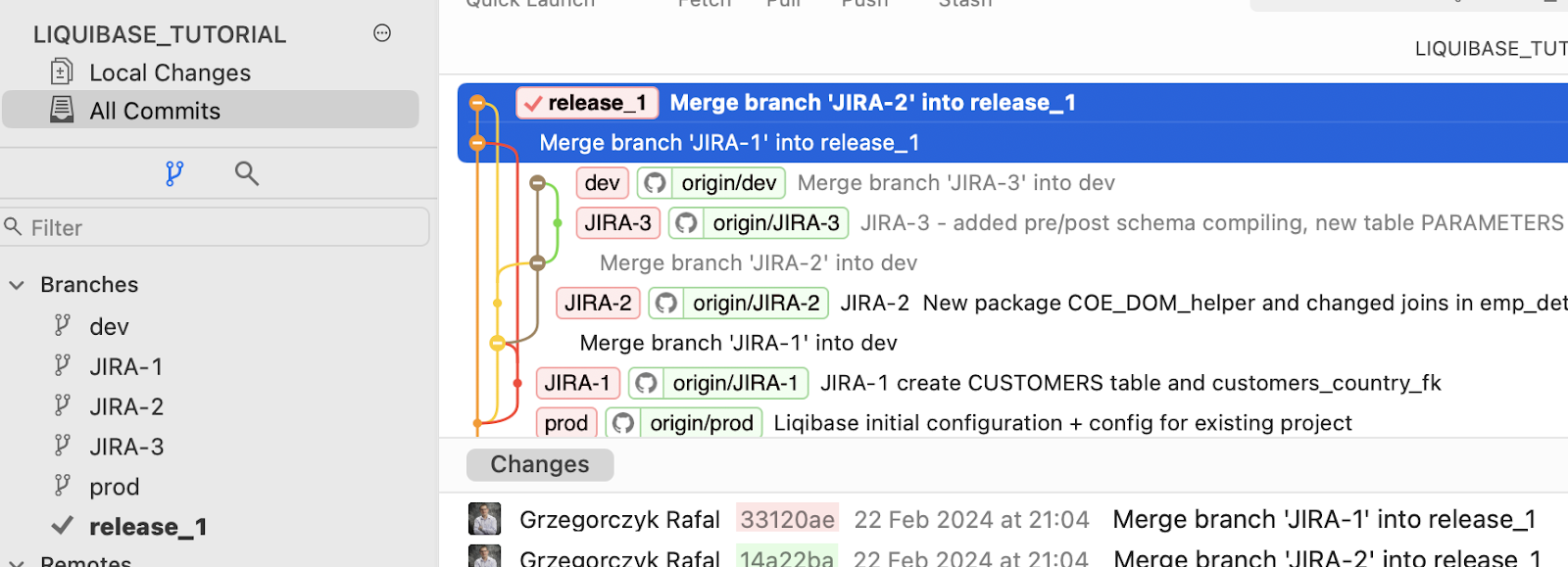
You’re almost ready to deploy to PROD.
- Merge release_1 branch to your PROD branch

UPDATE-SQL
Now, deploy changes from your PROD branch to your PROD database. Run update-sql to see what will be deployed:
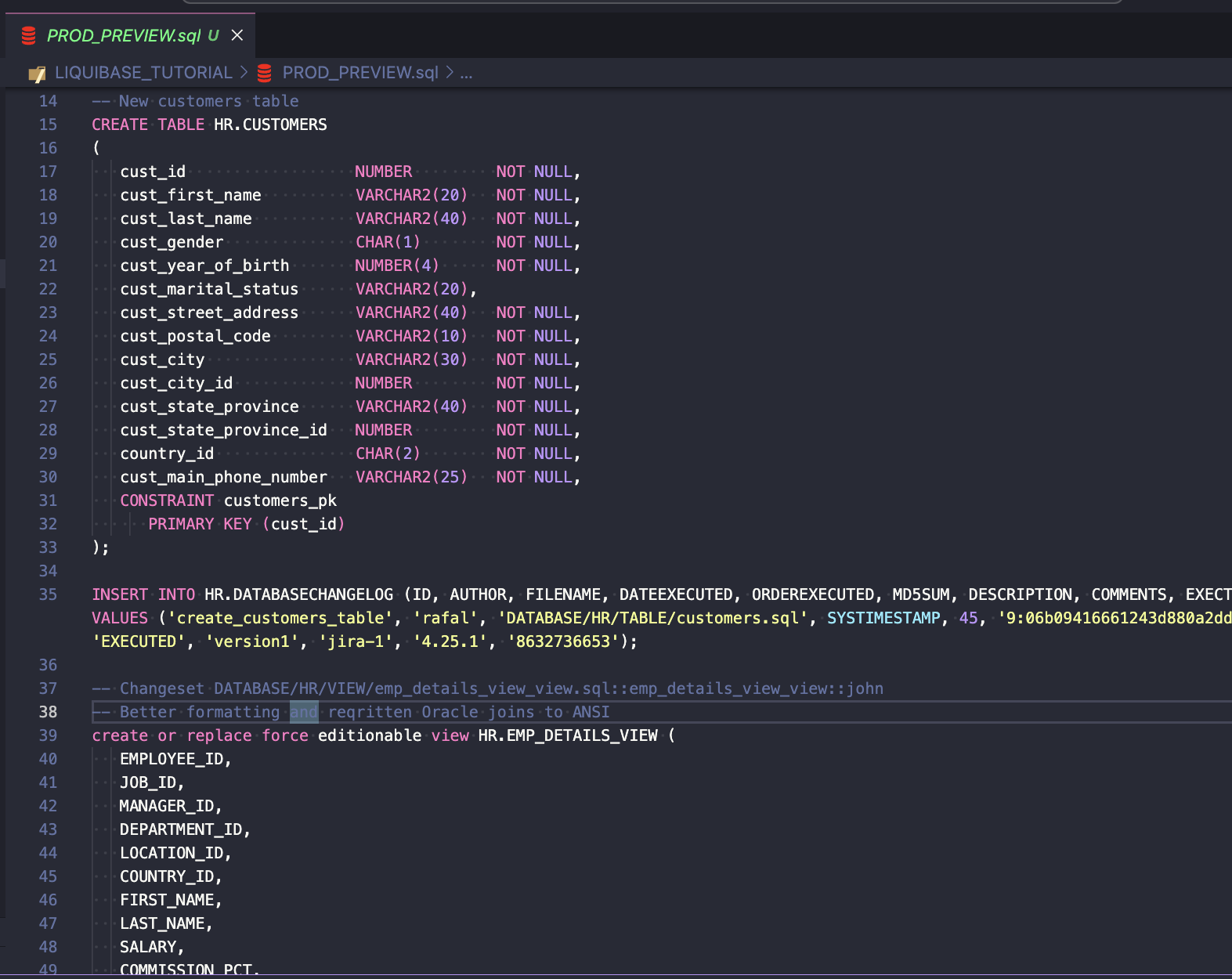
liquibase --defaults-file=prod.liquibase.properties update-sql --label-filter=JIRA-1,JIRA-2
There are no other pending changes on the PROD branch, so you could also run this command without the --label-filter parameter.
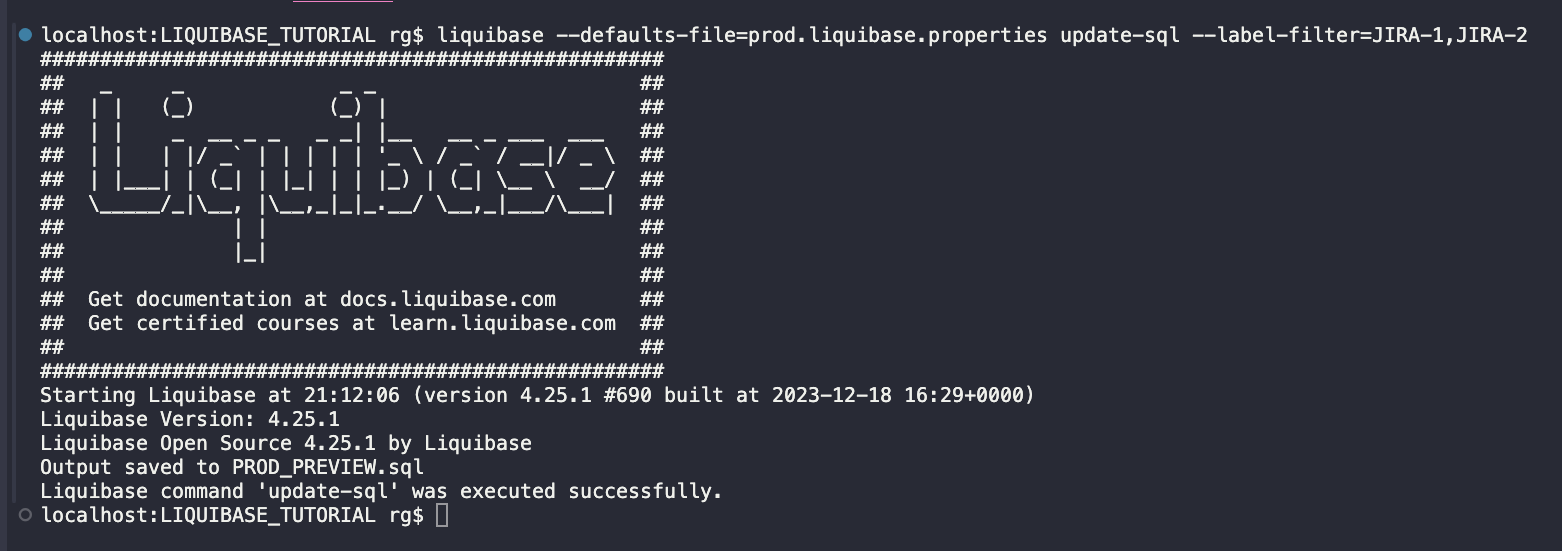
The script looks just like expected and contains only changes from tasks JIRA-1 and JIRA-2 (preview the full script here).
LIQUIBASE STATUS COMMAND
You can also use the status command to check what changesets will be deployed:
liquibase --defaults-file=prod.liquibase.properties status
The output looks like this:
5 changesets have not been applied to HR@jdbc:oracle:thin:@prod_low
DATABASE/HR/TABLE/customers.sql::create_customers_table::rafal
DATABASE/HR/VIEW/emp_details_view_view.sql::emp_details_view_view::john
DATABASE/HR/REF_CONSTRAINT/customers_country_fk.sql::customers_country_fk::rafal
DATABASE/HR/PACKAGE_SPEC/COE_DOM_helper.sql::COE_DOM_helper_spec::john
DATABASE/HR/PACKAGE_BODY/COE_DOM_helper.sql::COE_DOM_helper_body::john
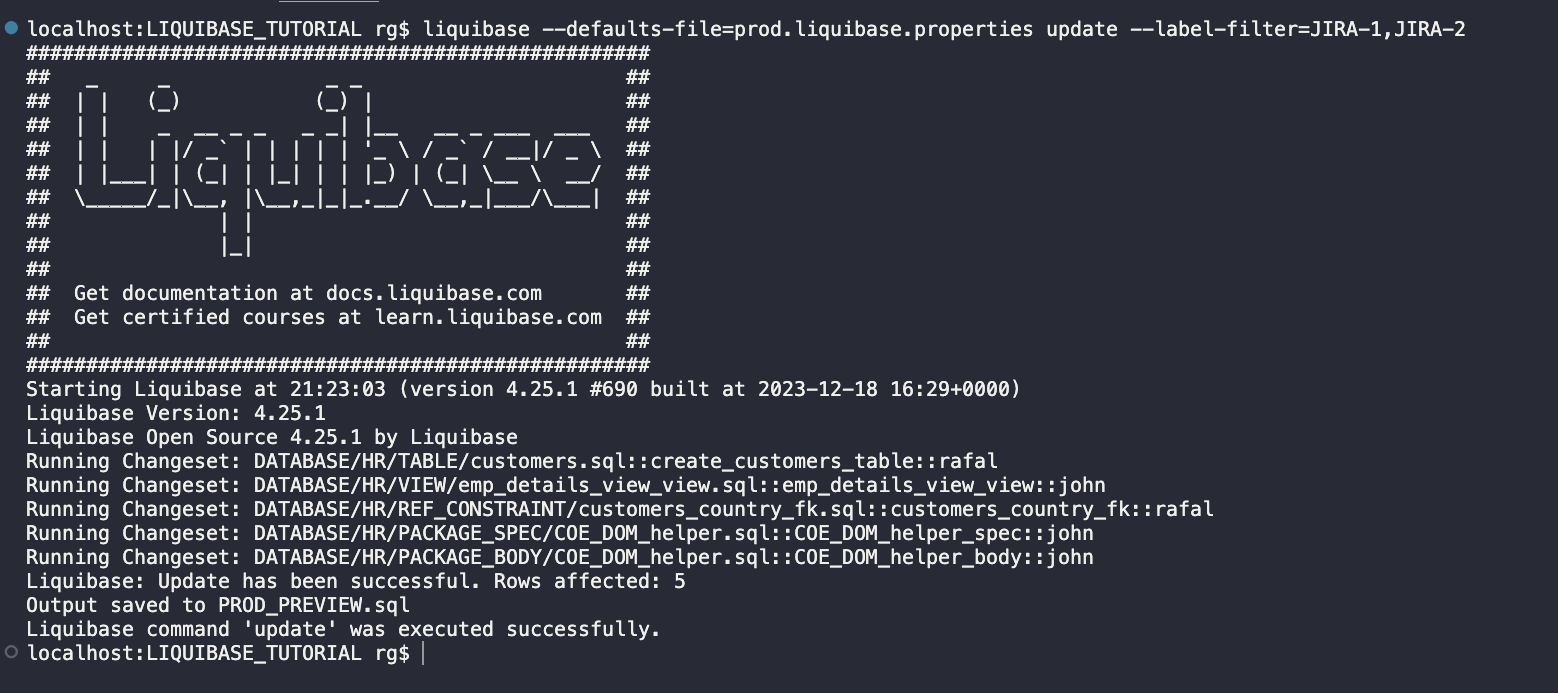
UPDATE
Steps:
Execute changes to the PROD database.
liquibase --defaults-file=prod.liquibase.properties update --label-filter=JIRA-1,JIRA-2
- Check DATABASECHANGELOG table in the PROD database.
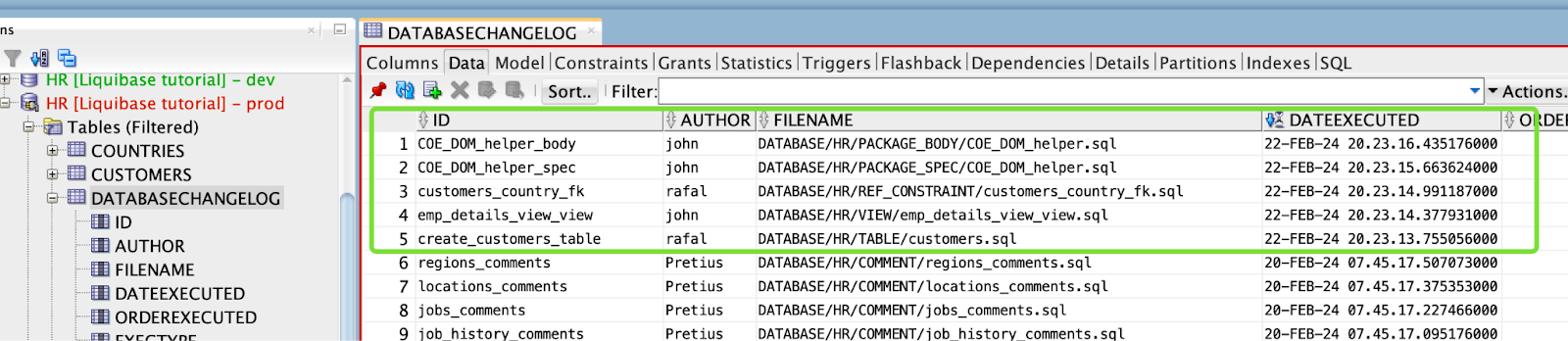
Everything was deployed as expected.
Deploy changes from JIRA-3 to PROD
It’s time to deploy the remaining changes from JIRA-3 to PROD.
Some GIT branching again
You’ll need to merge JIRA-3 to the newly created branch release_2 to do this. Then, merge the release_2 branch into PROD (repeat the steps mentioned above where applicable).

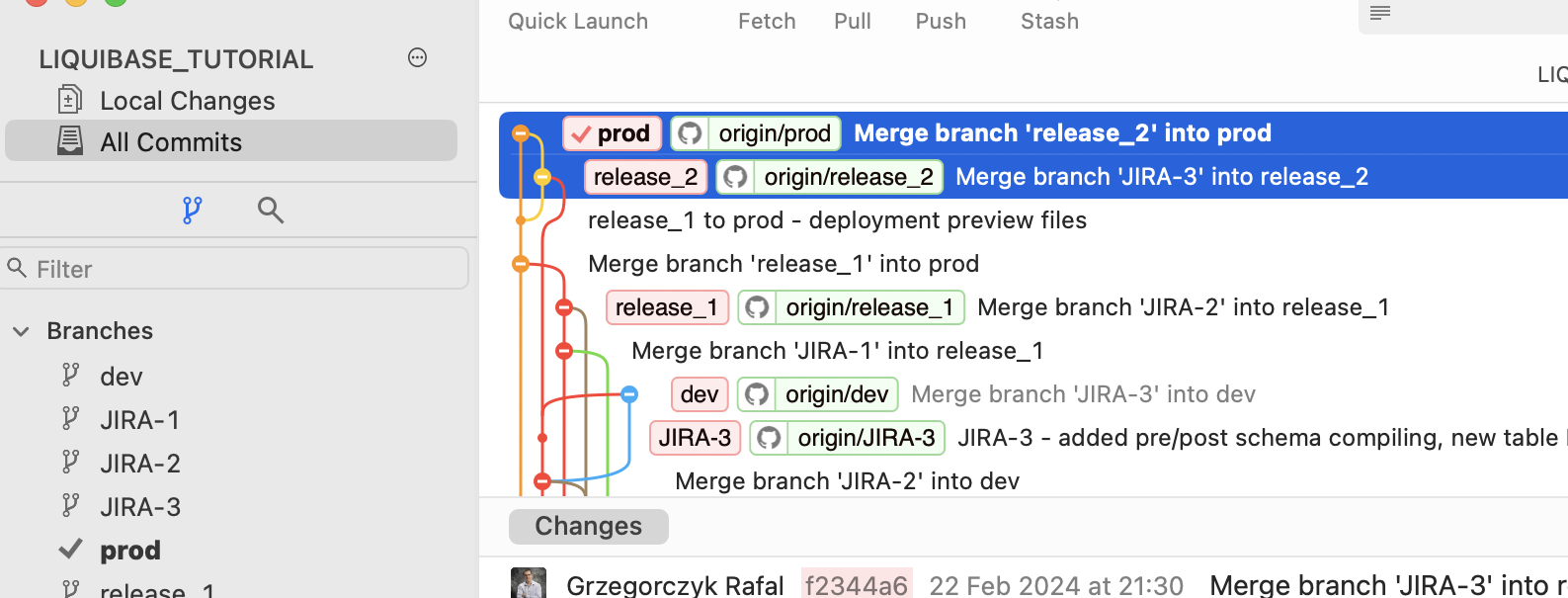
UPDATE-SQL
Steps:
- While being at the GIT PROD branch, preview what will be executed to the PROD database:
liquibase --defaults-file=prod.liquibase.properties update-sql --label-filter=JIRA-3
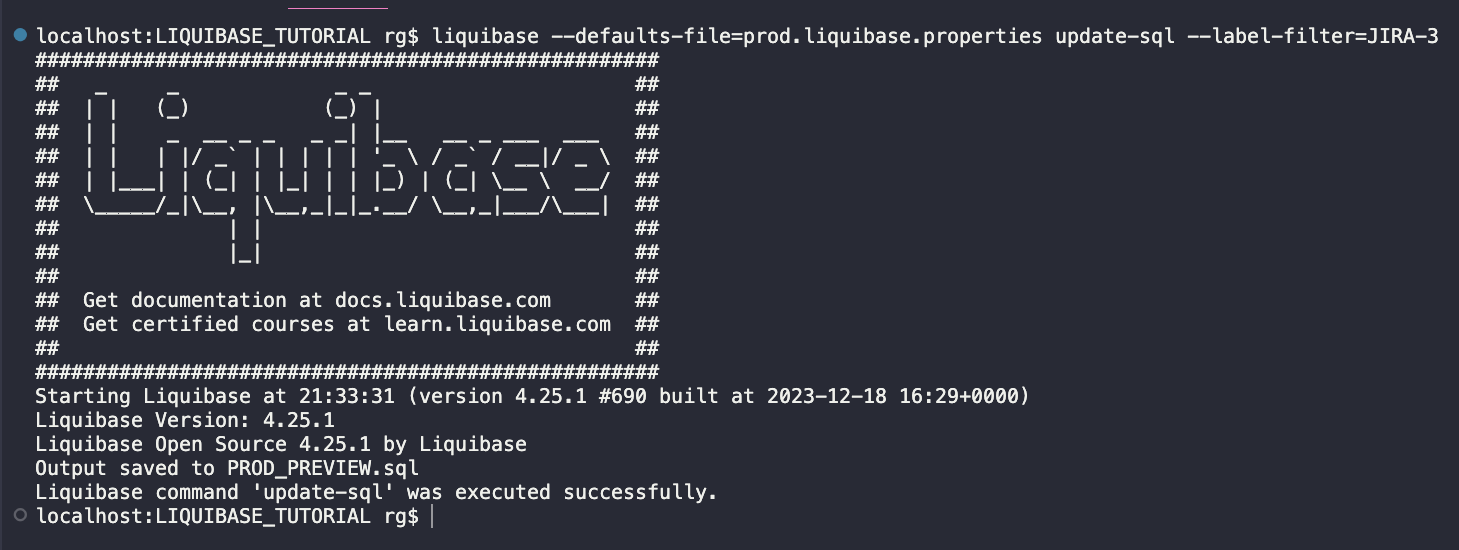
The file looks good (the full script preview is available here).
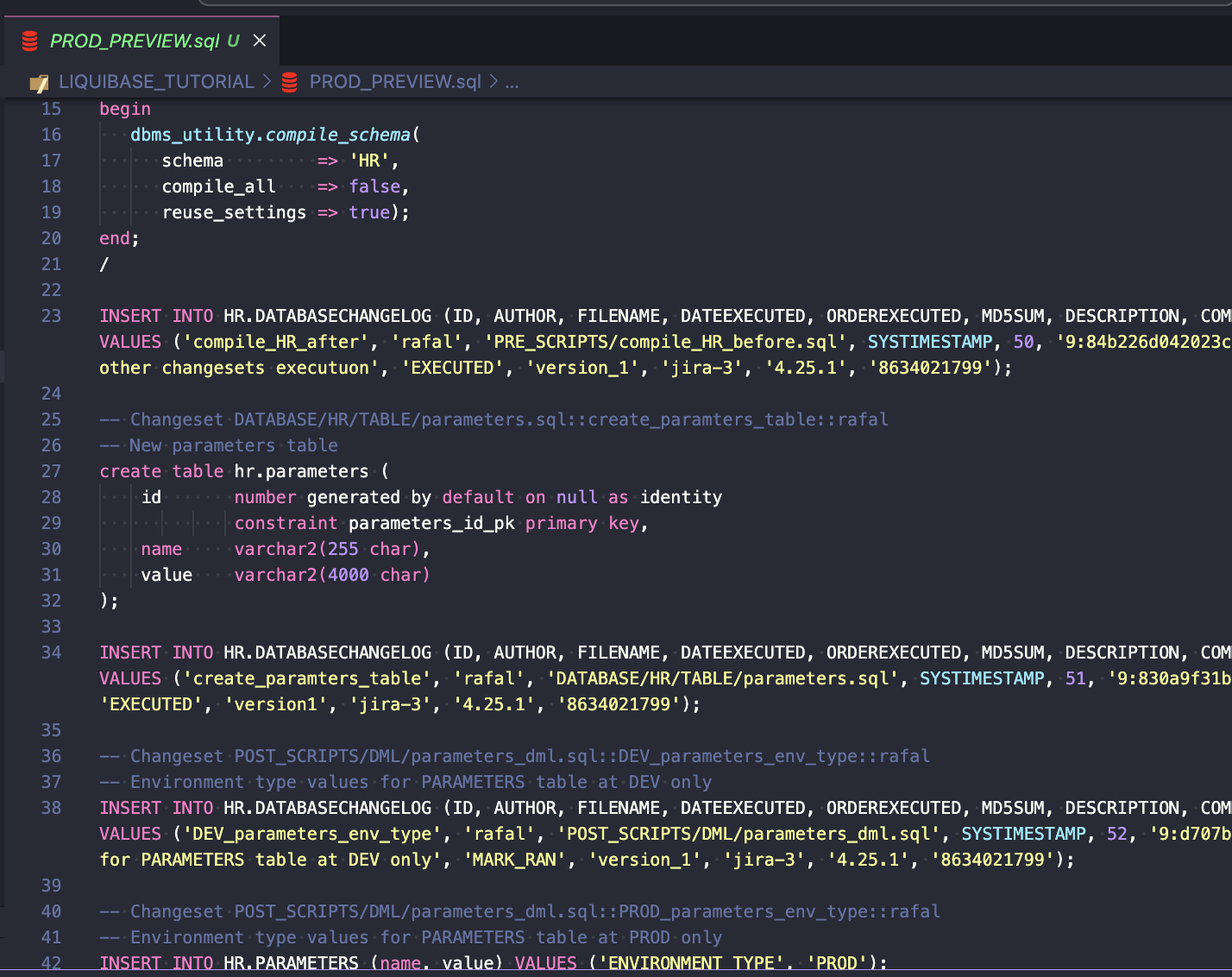
UPDATE
Steps:
Execute changes from the JIRA-3 task to the PROD database:
liquibase --defaults-file=prod.liquibase.properties update --label-filter=JIRA-3
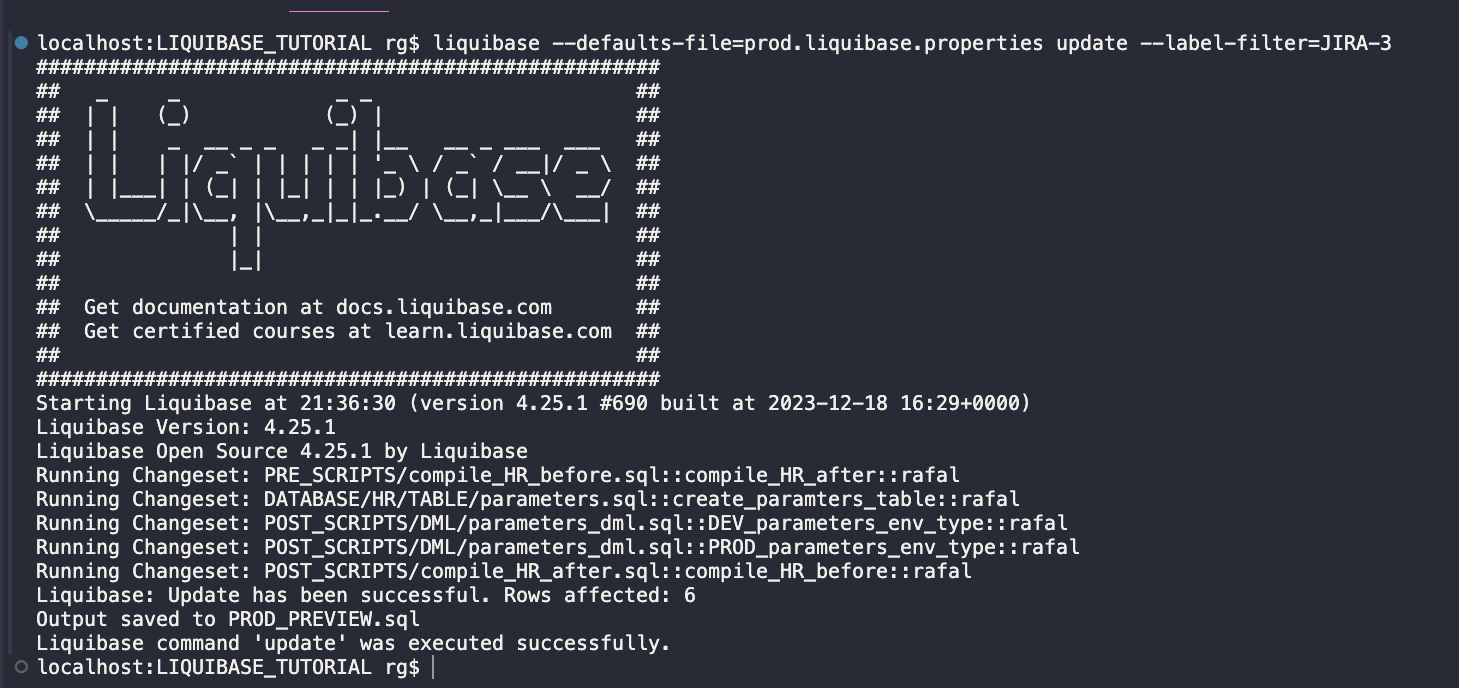
- Check the DATABASECHANGELOG table:
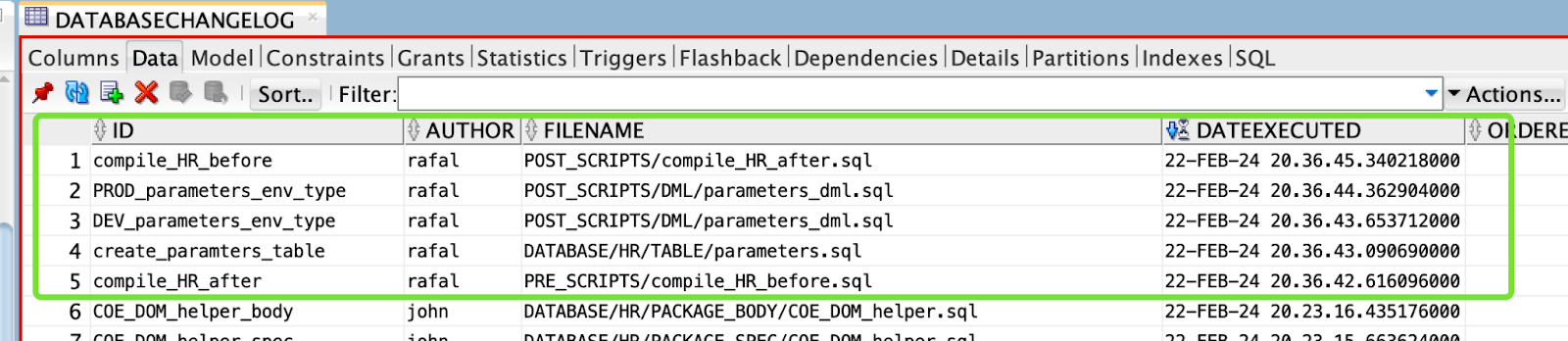
Finally, all changes from JIRA-1, JIRA-2 and JIRA-3 tasks are deployed to PROD. To check if this is true, run the STATUS command again:
liquibase --defaults-file=prod.liquibase.properties status
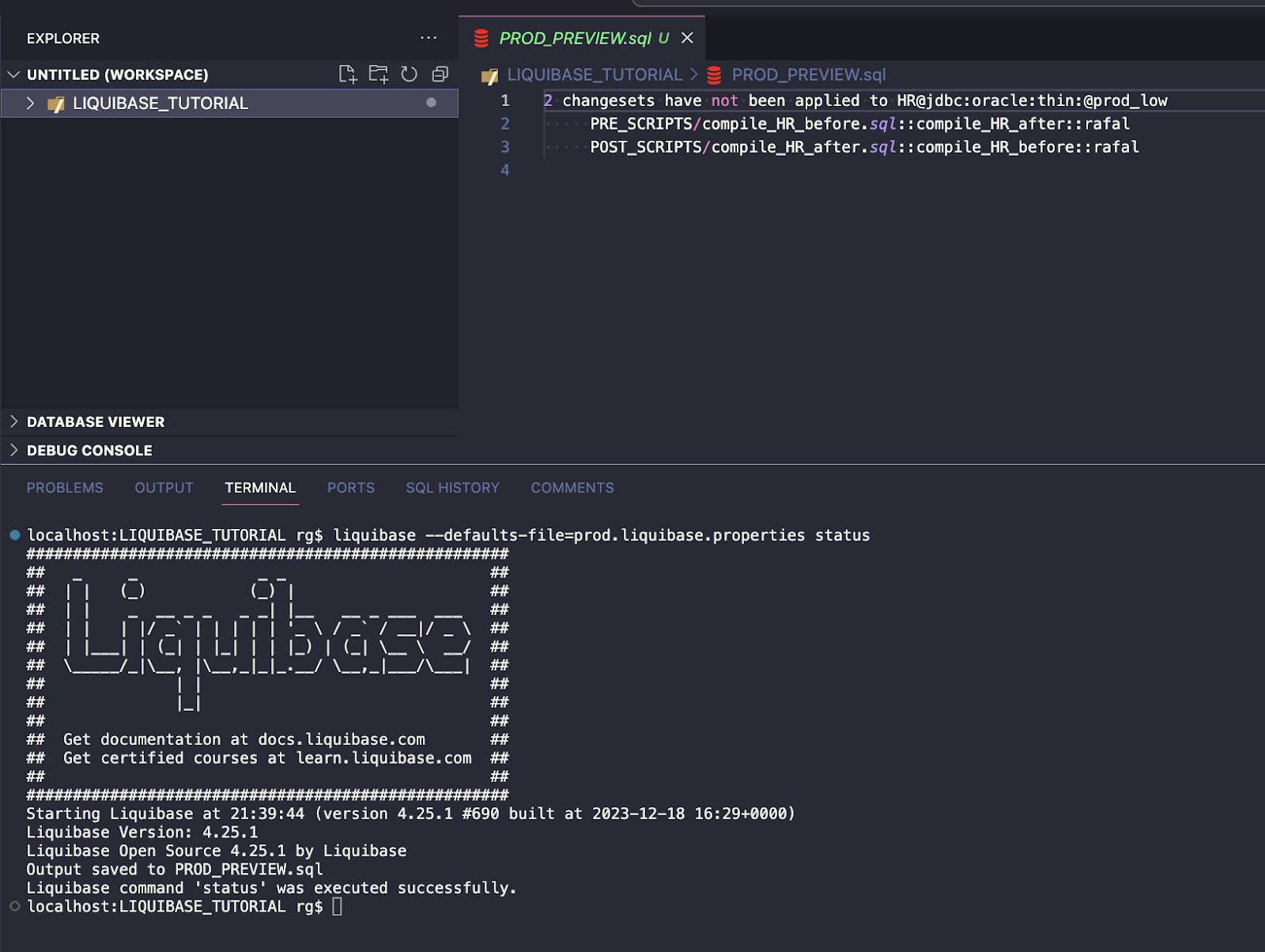
The output looks like this:
2 changesets have not been applied to HR@jdbc:oracle:thin:@prod_low
PRE_SCRIPTS/compile_HR_before.sql::compile_HR_after::rafal
POST_SCRIPTS/compile_HR_after.sql::compile_HR_before::rafal
This is true because these two changesets have the runAlways:true parameter set, so they will be executed every time.
Liquibase tutorial: Summary
What you read above are the best practices I learned during the last few years of working with Liquibase – during many projects and for various clients. I hope it will give you some insights regarding the possibilities of this free, open-source tool. Here are some recommendations for using this solution:
Before running the UPDATE command, always use UPDATE-SQL first to ensure that the code that will be executed is correct
Never run code generated with UPDATE-SQL manually. Use the UPDATE command to make changes
Make sure that all developers from your team use Liquibase and nobody is making secret changes directly to the database
Use contexts and labels
Use comments to describe your changes
Roll forward instead of making rollbacks. I know that this advice will have many opponents and supporters, probably in your project team too, so to prepare for the upcoming discussion, you can read about Liquibase rollbacks in the Liquibase documentation and in the great article by my colleague Łukasz Kosiciarz – Liquibase rollback: A smart way to do it with Jenkins